复杂度分析与渐进记号
1. 为什么需要复杂度分析?
在编写算法时,最朴素的问题就是:「这段代码运行得快不快?占多少内存?」我们可以用秒表计时,但这种方法有严重缺陷:
- 依赖硬件:同样的代码,在 i9 和 i3 上跑的时间完全不同
- 依赖数据:排序一个已排好序的数组 vs 一个逆序数组,时间差很多
- 不能预测:小规模测试跑得快,不代表 100 万数据时也能跑
复杂度分析正是为了解决这些问题而诞生的。它不关心具体多少秒,而是关注算法的运行时间如何随输入规模
2. 渐进记号:大 O、大 Ω、大 Θ
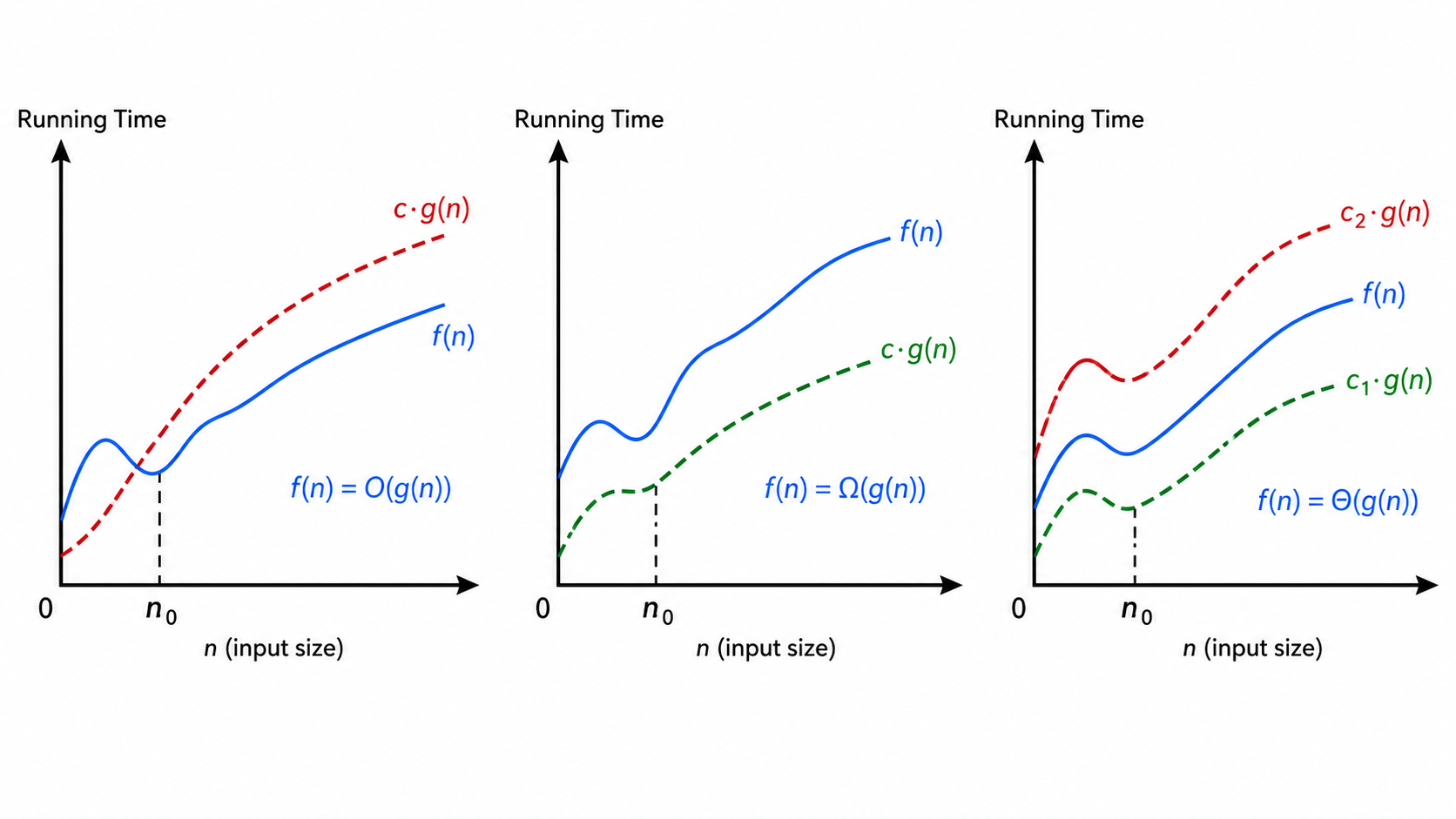
2.1 大 O 记号(上界)
定义:
用人话说:
例:
2.2 大 Ω 记号(下界)
定义:
大 Ω 给出了最好情况的下界。例如,比较排序算法的下界是
2.3 大 Θ 记号(紧确界)
定义:
大 Θ 是最精确的描述——它说明两个函数增长速度相同。例如,快速排序的平均时间复杂度是
2.4 渐进分析的实用法则
在实践中,我们通常这样分析:
- 忽略常数因子:
和 都是 - 忽略低阶项:
就是 - 只留增长最快的项:
仍是 (指数压倒多项式)
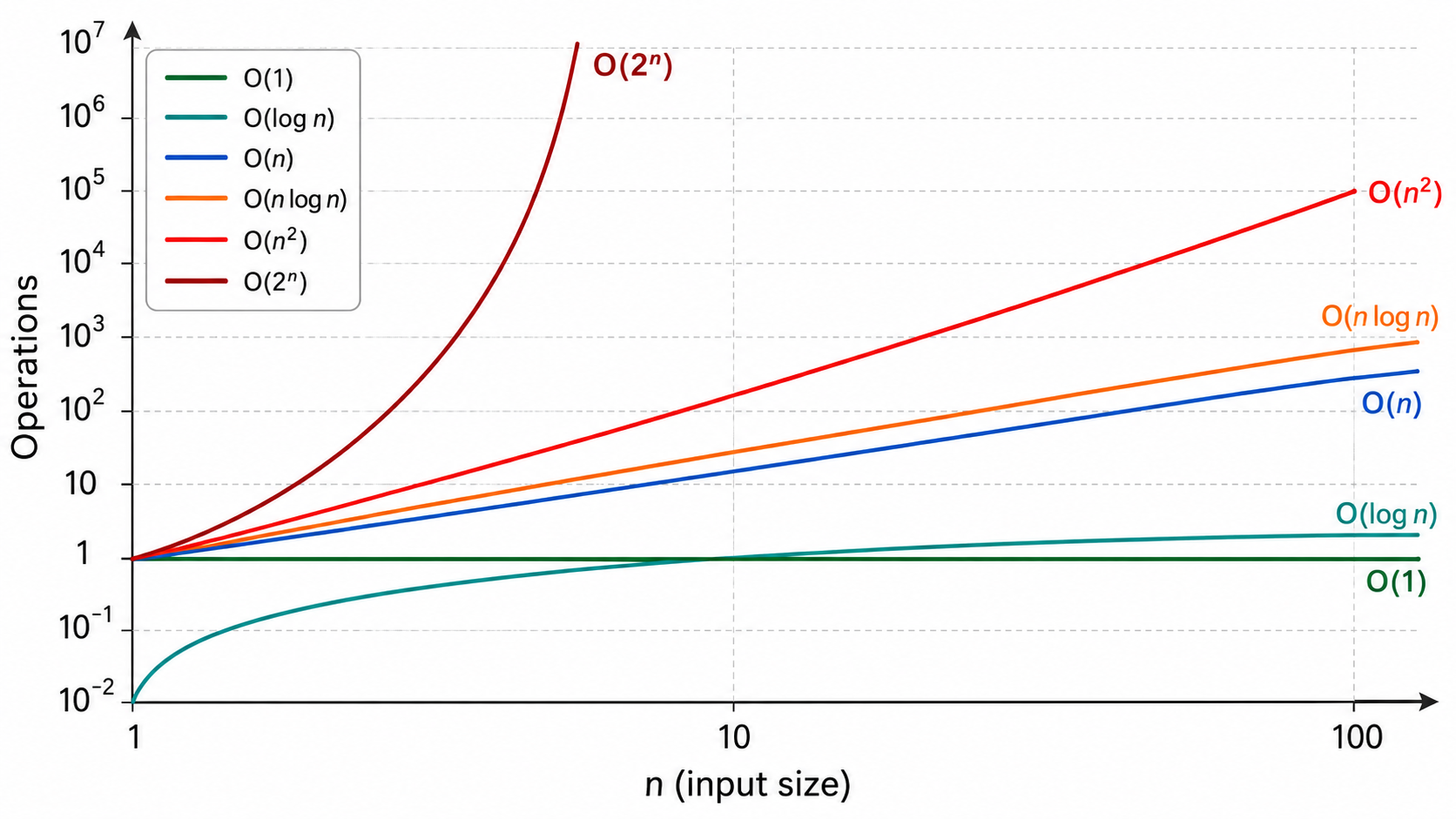
3. 常见复杂度等级
按照增长速度从低到高排列(越往后越"慢"):
| 记号 | 名称 | 典型算法 | ||||
|---|---|---|---|---|---|---|
| 常数 | 1 | 1 | 1 | 1 | 数组索引、哈希查找 | |
| 对数 | ~3 | ~10 | ~20 | ~30 | 二分查找、平衡树查找 | |
| 线性 | 10 | 不可行 | 线性搜索、数组遍历 | |||
| 线性对数 | ~33 | ~ | ~ | 不可行 | 归并排序、堆排序 | |
| 平方 | 100 | 不可行 | 不可行 | 冒泡排序、简单DP | ||
| 立方 | 1000 | 不可行 | 不可行 | Floyd-Warshall | ||
| 指数 | 1024 | 灾难 | 灾难 | 灾难 | 暴力搜索子集 | |
| 阶乘 | 灾难 | 灾难 | 灾难 | 暴力旅行商问题 |
关键洞察:当
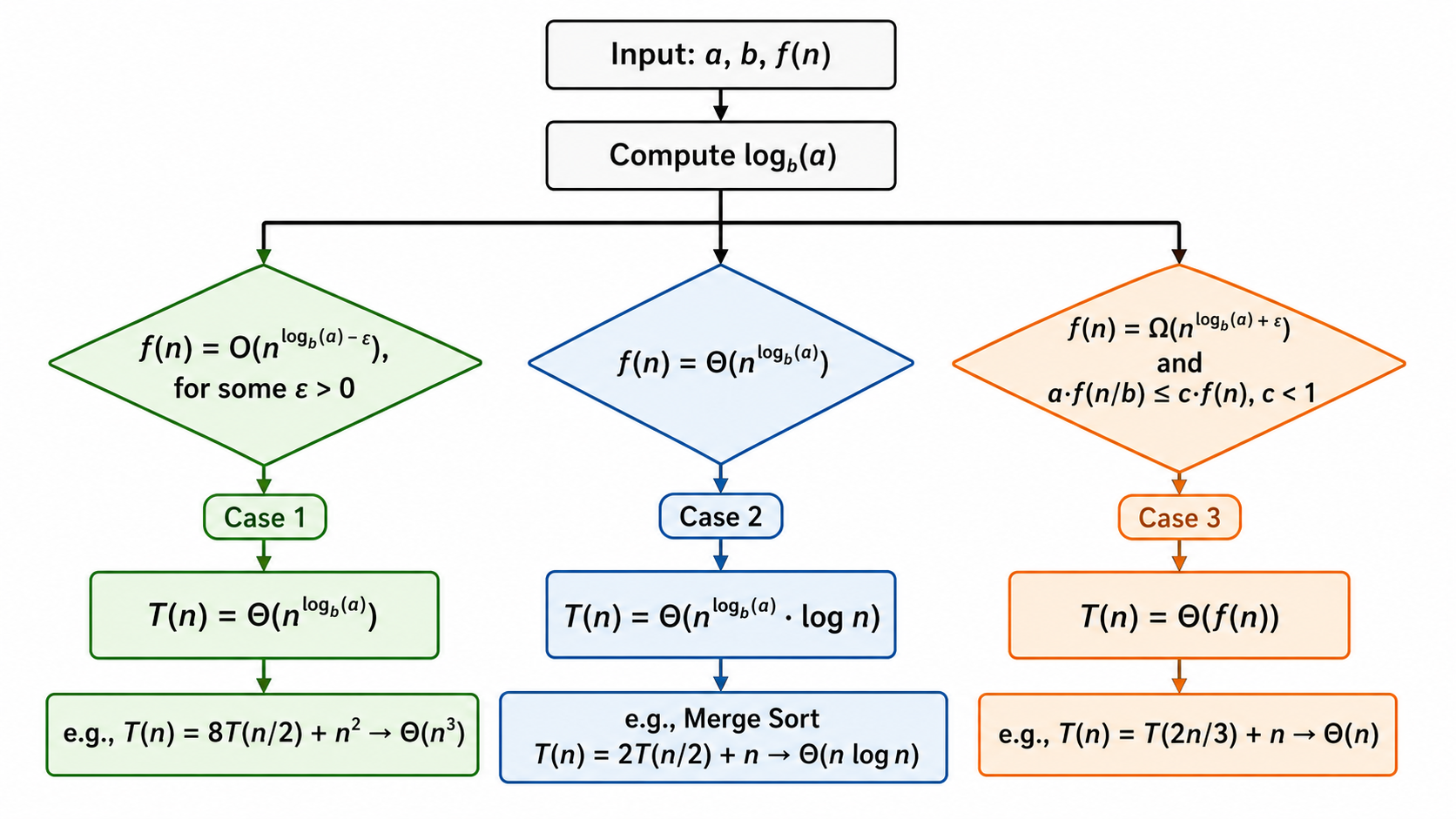
4. 主定理(Master Theorem)
对于分治算法,其时间复杂度通常满足递推式:
其中:
:子问题的个数( ) :每次将问题规模缩小的因子( ) :分解与合并的代价
主定理给出了三种情形下的解:
情形 1:叶节点主导
若
直觉:合并代价比子问题增长慢,复杂度由叶子节点决定。
情形 2:均匀分布
若
直觉:每层的代价都差不多,乘上层数
情形 3:根节点主导
若
直觉:合并代价比子问题增长快,复杂度由根节点决定。
经典例子:
- 归并排序:
, , , ,属于情形 2, 。 - 二分查找:
, , , ,情形 2, 。 - Strassen 矩阵乘法:
, , ,情形 1, 。
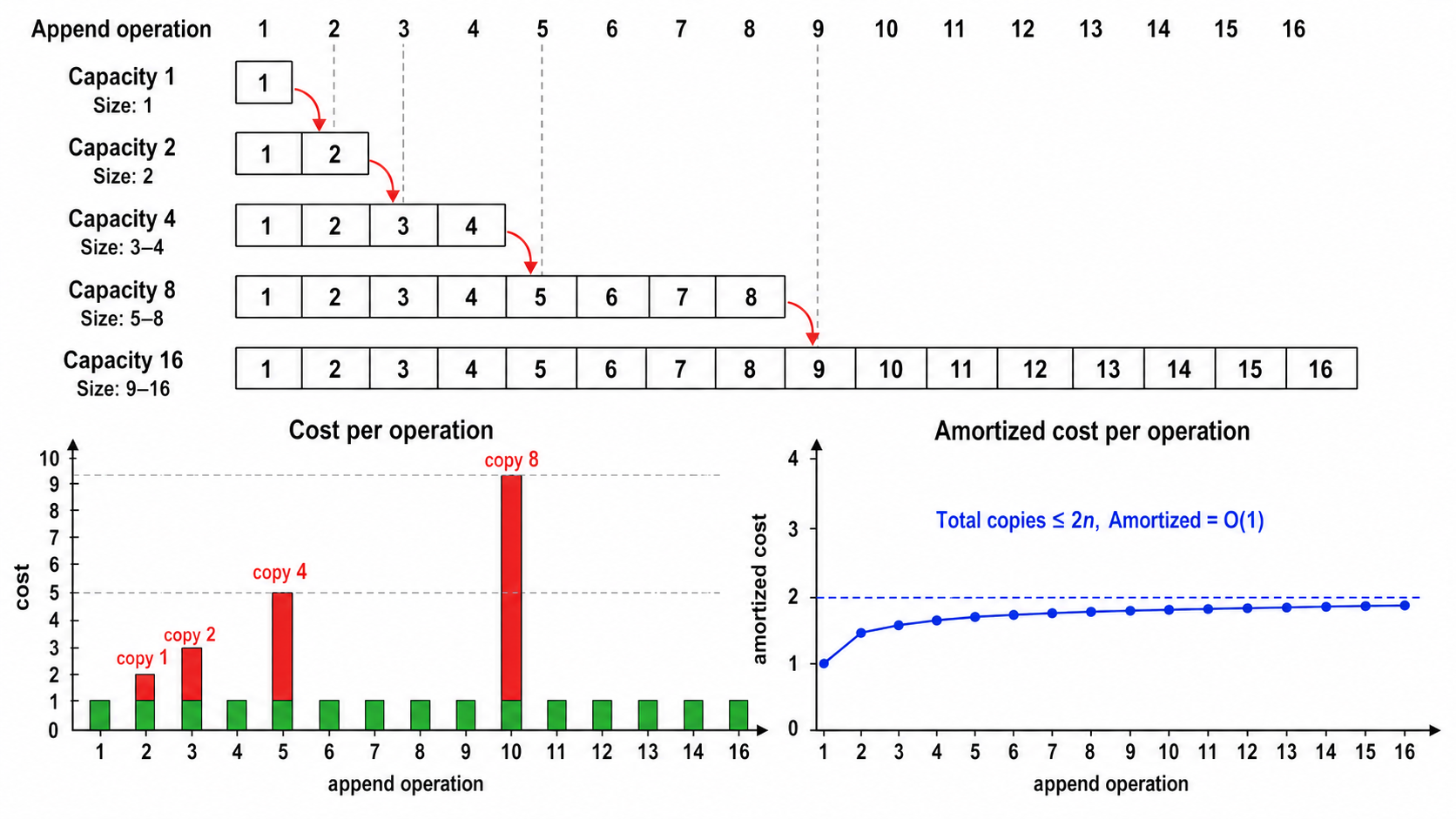
5. 均摊分析(Amortized Analysis)
均摊分析关注的是一系列操作的平均代价,而不是单次操作的最坏情况。它解释了为什么某些操作虽然偶尔很"贵",但平均下来很便宜。
5.1 聚合分析(Aggregate Method)
直接计算
经典例子——动态数组(Python 的 list.append):
当一个数组满时,需要分配一个更大的数组(通常是原来的 2 倍),然后将所有元素复制过去。这个操作是
均摊分析:经过
所以总代价为
5.2 记账法(Accounting Method)
给每次便宜的操作多收一点"费用"存入银行(credit),用来支付偶尔出现的贵操作的代价。
例子:动态数组的 append。
- 每次 append 收 3 元:1 元支付本次插入,2 元存入 credit
- 当数组满了需要扩容时,已有足够 credit 支付复制操作
- 结果:每次操作的均摊代价为
5.3 势能法(Potential Method)
定义势能函数
对于动态数组,可以定义
6. 空间复杂度
除了时间,我们还需要考虑空间复杂度——算法运行中占用的额外内存(不包括输入数据本身)。
空间:原地算法,只使用常数额外空间(如冒泡排序) 空间:需要与输入同规模的额外空间(如归并排序的临时数组) 空间:递归栈的空间(如平衡树的递归操作)
时空权衡:在许多算法中,时间和空间是可以互换的。例如,哈希表用
本章总结
复杂度分析是算法设计的基石。本章我们学习了:
- 渐进记号:大 O(上界)、大 Ω(下界)、大 Θ(紧确界)是描述复杂度的数学语言
- 常见复杂度等级:从
到 ,理解各等级的增速差异是选择算法的前提 - 主定理:提供了分治算法复杂度分析的标准工具,三种情形覆盖了大多数常见递推式
- 均摊分析:解释了看似"贵"的操作如何通过长期平均变得"便宜",动态数组是最经典的例子
- 空间复杂度:时间和空间常常需要权衡,好的设计能在这两者间找到平衡
这些工具将在后续每个章节中被反复使用——每当我们介绍一个新算法,第一件事就是分析它的复杂度。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press. (CLRS 经典教材,第 3、17 章)
- Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley.
- Kleinberg, J., & Tardos, E. (2005). Algorithm Design. Pearson.
下一章:数组、链表与哈希表