朴素贝叶斯与贝叶斯网络
1. 条件独立假设:为什么叫"朴素"
1.1 从高斯贝叶斯到朴素贝叶斯
在 ml02 中,我们实现了高斯贝叶斯分类器,它使用多元高斯分布来建模
朴素贝叶斯(Naive Bayes)做了一个"天真"但极其有效的简化:假设在给定类别的条件下,所有特征之间相互独立。
这个假设"朴素"在:现实世界中特征之间几乎总是相关的。例如,"身高"和"体重"在给定性别(类别)的条件下仍然相关——高的人更可能重。但朴素贝叶斯忽略这些相关性,假设身高和体重在"给定性别"后独立。
然而,尽管这个假设在现实中通常不成立,朴素贝叶斯在实际应用中表现出奇地好——原因不仅是它计算简单,更重要的是:即使概率估计不准确,只要各类别的概率相对顺序正确,分类决策就是对的。
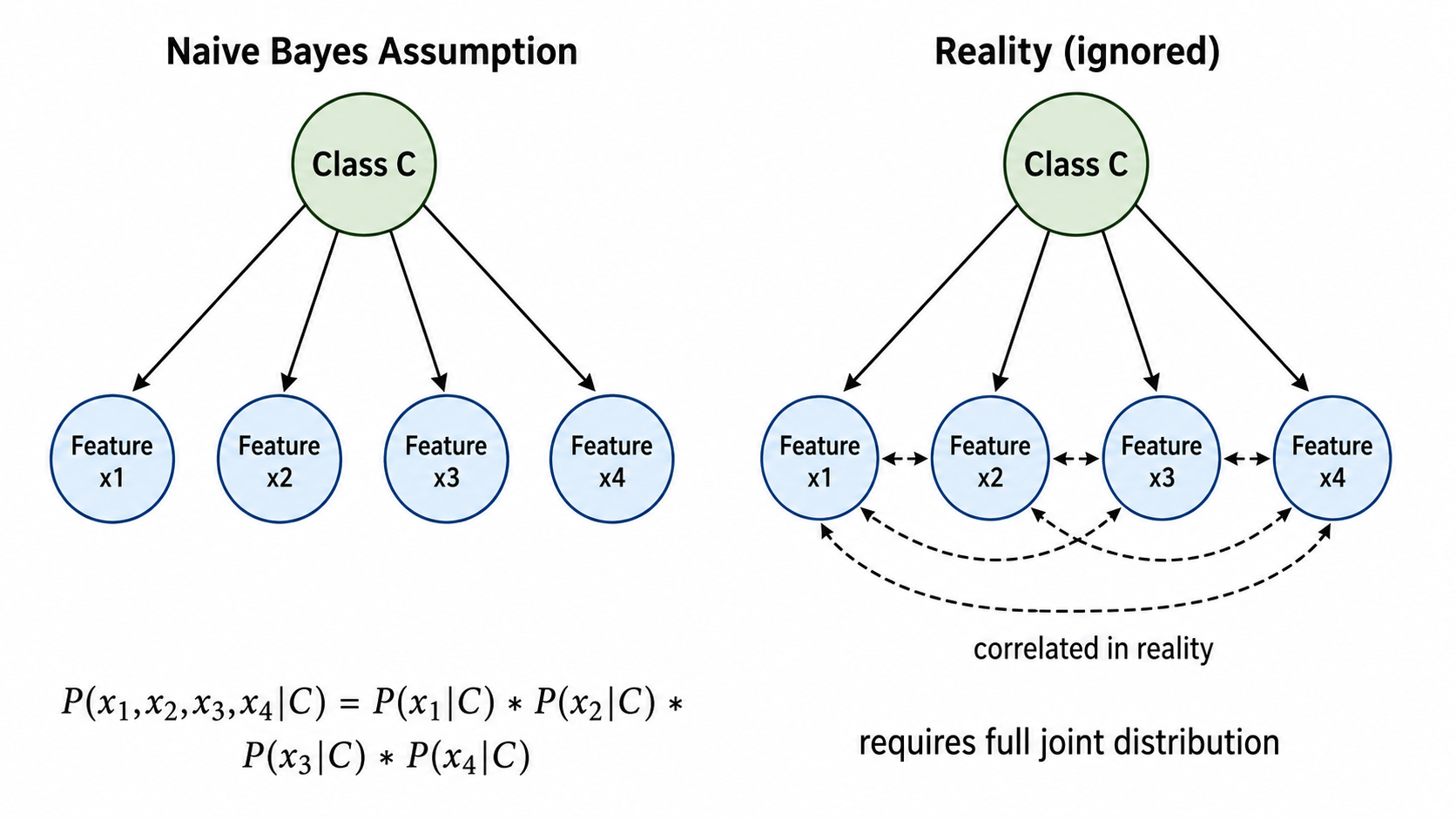
1.2 为什么"朴素"反而有效?
三点原因解释了朴素贝叶斯的意外成功:
分类只需要 argmax:即使
的绝对值不准,只要各类别间的相对顺序正确,决策就不受影响。朴素贝叶斯虽然高估或低估了概率,但高估的方向往往对各类别一致。 相关特征互相加强而非混淆:假设两个高度相关的特征(如"免费"和"中奖"在垃圾邮件中),它们在独立性假设下会被相乘:
。即使忽略了它们"同时出现时概率应该更高"的修正,它们各自的高概率也足以让垃圾邮件的联合似然很高。 零参数 vs 指数参数:朴素贝叶斯只需要
个参数(每个特征-类别对只需 2 个参数),而完整的多变量分布需要 个参数( 是离散化级别)。这大幅降低了方差。
1.3 朴素贝叶斯的分类决策
根据贝叶斯定理和条件独立假设:
取对数得到判别函数:
决策规则:
2. 三种朴素贝叶斯变体
根据特征的类型,
2.1 高斯朴素贝叶斯(GaussianNB)
适用于连续特征。假设每个特征在每个类别下服从一维高斯分布:
需要估计:各类别各特征的均值
与完整高斯贝叶斯的区别:GaussianNB 假设各类别各特征之间独立,即协方差矩阵是对角的(
2.2 多项朴素贝叶斯(MultinomialNB)
适用于离散计数特征(尤其是文本的词频/词袋表示)。假设特征服从多项分布:
其中:
:类别 中特征 的总出现次数 :类别 中所有特征的总出现次数 :平滑参数(见 2.4 节)
MultinomialNB 是文本分类(垃圾邮件检测、新闻分类、情感分析)的经典基准模型。在著名的 20 Newsgroups 数据集上,一个简单的 MultinomialNB 能达到 80%+ 的准确率。
2.3 伯努利朴素贝叶斯(BernoulliNB)
适用于二值特征(特征取值仅为 0 或 1)。假设特征服从伯努利分布:
模型直接建模
BernoulliNB 也常用于文本分类——它判断"词语是否出现"而不关心出现的次数。对于短文本(如推文),BernoulliNB 可能比 MultinomialNB 效果更好。
| 变体 | 特征类型 | 似然函数 | 典型应用 |
|---|---|---|---|
| GaussianNB | 连续值 | 一般分类任务 | |
| MultinomialNB | 非负计数 | 文本分类、词频向量 | |
| BernoulliNB | 二值 (0/1) | 短文本、特征存在/缺失 |
2.4 拉普拉斯平滑(Laplace Smoothing)
朴素贝叶斯有一个致命弱点:如果某个特征在某类别中从未在训练集中出现,那么
拉普拉斯平滑(也称为加一平滑)解决了这个问题:
其中
:拉普拉斯平滑(Laplace Smoothing) :Lidstone Smoothing :无平滑(MLE)
平滑就像是给每种可能性赋予了一个"虚拟的"先验计数
在 GaussianNB 中,方差估计也需要类似处理:var_smoothing 参数在计算方差时加上一个小的常数,防止方差为零(当某特征在某类别中所有样本取值完全相同时会发生)。
3. 贝叶斯网络简介
3.1 从朴素贝叶斯到贝叶斯网络
朴素贝叶斯假设所有特征在给定类别后完全独立——这是一个全连接但被类别节点"阻断"的结构。贝叶斯网络(Bayesian Network)放松了这个假设,允许我们显式地建模特征之间的依赖关系。
一个贝叶斯网络由两部分组成:
- 有向无环图(DAG)
:节点代表随机变量,有向边 表示 对 有直接因果影响 - 条件概率表(CPT):每个节点的概率分布,条件于其父节点
联合概率分布分解为:
其中
3.2 d-分离与条件独立
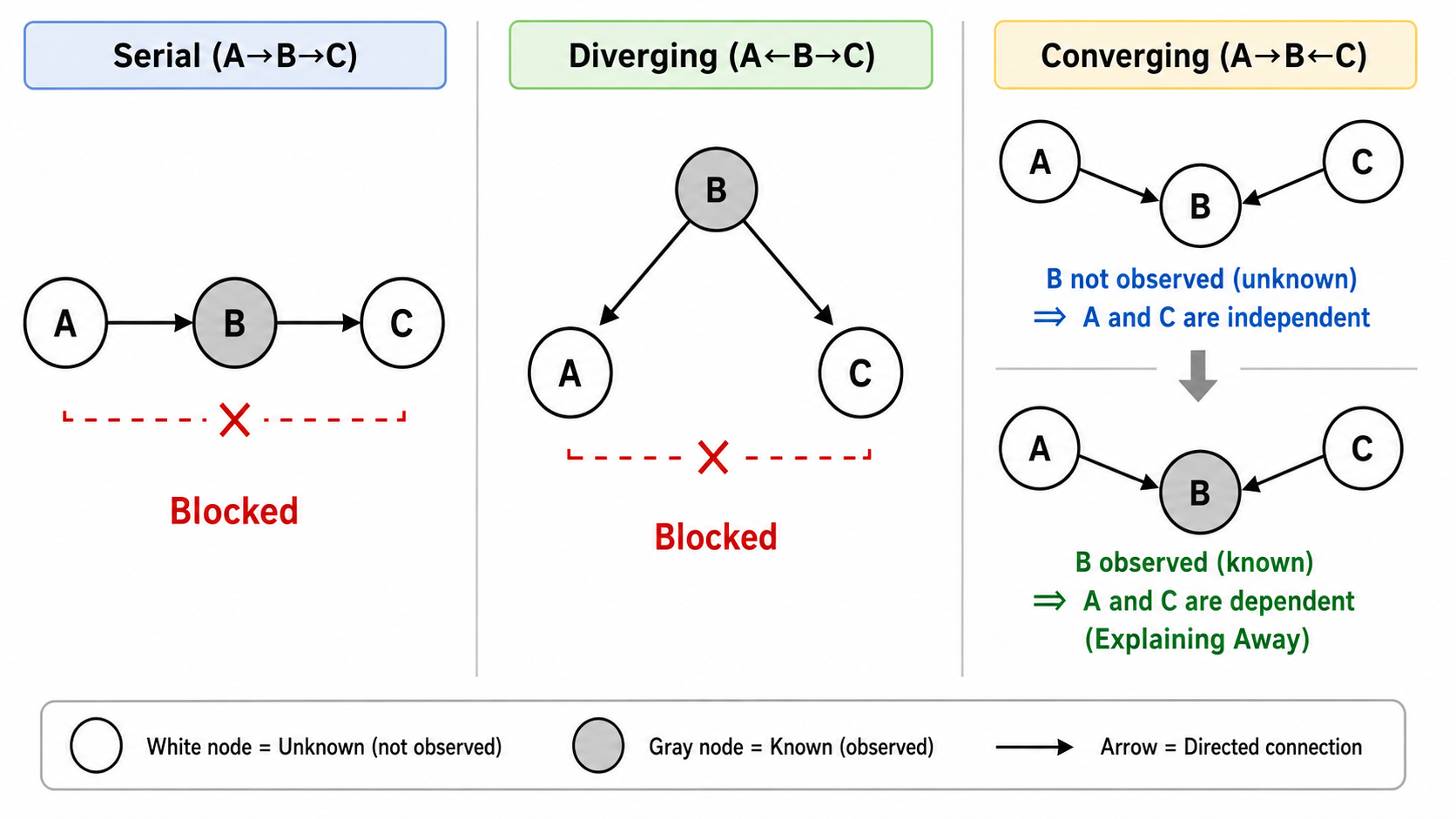
贝叶斯网络中最核心的推理工具是 d-分离(d-separation)。它用图结构来判断任意两组变量是否在给定第三组变量后条件独立。
三种基本连接模式:
- 串行连接
:若已知 ,则 和 条件独立(信息被 阻断) - 发散连接
:若已知 ,则 和 条件独立(共同原因 解释了 和 的关联) - 汇聚连接
:若已知 (或 的任何后代),则 和 不再是条件独立的(explaining away——解释消除现象)
汇聚连接(v-structure)是反直觉的:两个无关的原因,在知道了结果后反而"变得相关"。例如:草坪湿了(
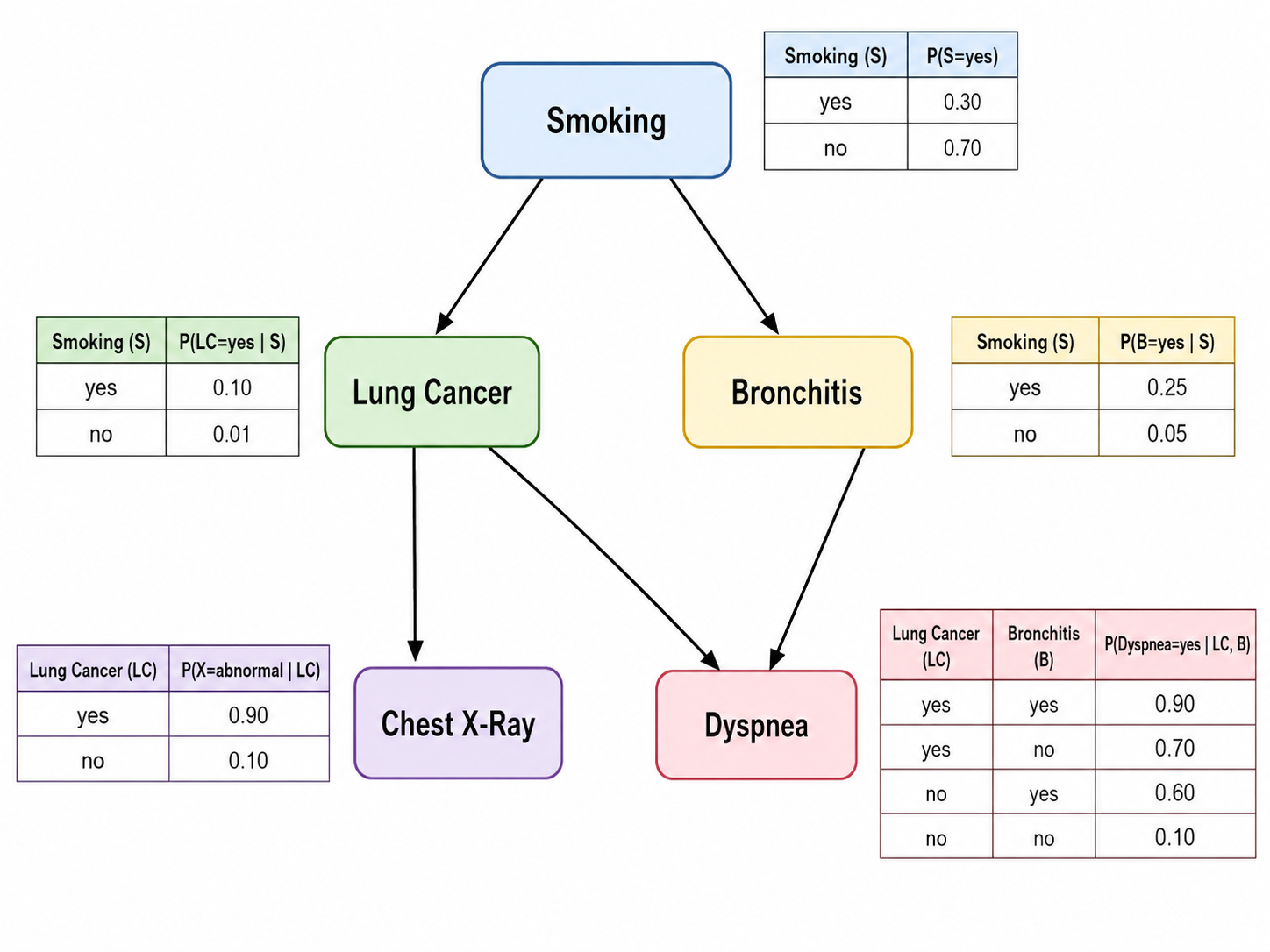
3.3 CPT 与推理
条件概率表(CPT)存储每个节点的条件概率分布。对于离散变量,一个节点
其中
贝叶斯网络支持多种推理:
- 诊断推理:从结果推断原因(
) - 预测推理:从原因推断结果(
) - ** intercausal 推理**:多个原因之间的推理(explaining away)
4. 从零实现朴素贝叶斯
4.1 GaussianNB 的核心实现
class GaussianNB:
def fit(self, X, y):
for each class j:
for each feature i:
mu[j, i] = mean of feature i in class j
sigma2[j, i] = var of feature i in class j + epsilon (smoothing)
def predict(self, X):
for each sample:
for each class j:
log_prob[j] = log P(omega_j) + sum_i log N(x_i | mu[j,i], sigma2[j,i])
return argmax(log_prob)与完整高斯贝叶斯的关键区别:不需要协方差矩阵。每个特征独立建模,参数复杂度从
4.2 MultinomialNB 的特征计数
# 对每个类别,统计每个特征的出现次数
feature_count[j, i] = sum of feature i across samples in class j
# 加上平滑
P(x_i | class j) = (feature_count[j, i] + alpha) / (sum(feature_count[j]) + alpha * d)对于文本分类,特征向量
本章总结
| 概念 | 公式/描述 | 关键点 |
|---|---|---|
| 条件独立假设 | "朴素"的来源,大幅减少参数 | |
| GaussianNB | 连续特征,对角协方差 | |
| MultinomialNB | 计数特征,文本分类 | |
| BernoulliNB | 二值特征 | |
| 拉普拉斯平滑 | 防止零概率问题 | |
| 贝叶斯网络 | DAG + CPT,建模特征依赖 | |
| d-分离 | 图结构推断条件独立 | 串行/发散/汇聚三种模式 |
| Explaining Away | 反直觉的推理模式 |
参考
- Maron, M. E. (1961). Automatic indexing: An experimental inquiry. Journal of the ACM, 8(3), 404-417. (朴素贝叶斯在文本分类的最早应用之一)
- Friedman, N., Geiger, D., & Goldszmidt, M. (1997). Bayesian network classifiers. Machine Learning, 29(2-3), 131-163. DOI: 10.1023/A:1007465528199
- Domingos, P., & Pazzani, M. (1997). On the optimality of the simple Bayesian classifier under zero-one loss. Machine Learning, 29(2-3), 103-130. DOI: 10.1023/A:1007413511361 (为什么"朴素"反而有效)
- Pearl, J. (1988). Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann. (贝叶斯网络的奠基之作)
- Zhang, H. (2004). The optimality of naive Bayes. AAAI, 17(1), 562-567.
- Koller, D., & Friedman, N. (2009). Probabilistic Graphical Models: Principles and Techniques. MIT Press. ISBN: 9780262013192
- Manning, C. D., Raghavan, P., & Schuetze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. DOI: 10.1017/CBO9780511809071 第 13 章(文本分类与朴素贝叶斯)
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. DOI: 10.1007/978-0-387-45528-0 第 8 章(概率图模型)