逻辑回归与分类
1. 从回归到分类
在前一章中,我们学习了线性回归——预测一个连续的数值。但现实中很多问题需要回答「是」或「否」:
- 这封邮件是垃圾邮件吗?(是/否)
- 这个肿瘤是恶性的吗?(是/否)
- 这张图片是猫还是狗?(猫/狗)
这些问题属于分类(Classification)。分类的目标是将输入
为什么不能直接用线性回归做分类?
假设我们尝试用一个线性模型
输出范围不对:线性模型的输出可能是任意实数(
到 ),而我们需要一个介于 0 和 1 之间的值来表示「属于正类的概率」。 对异常值敏感:一个极端的数据点可能大幅拉扯决策边界。在分类问题中,一个点只要被正确放在了边界的一侧即可,不应要求预测值「逼近」标签。
决策边界的解释:我们希望
时判为正类, 时判为负类。线性回归的输出无法满足这种概率解释。
解决方案:给线性模型的输出套上一个非线性函数,将其「压缩」到
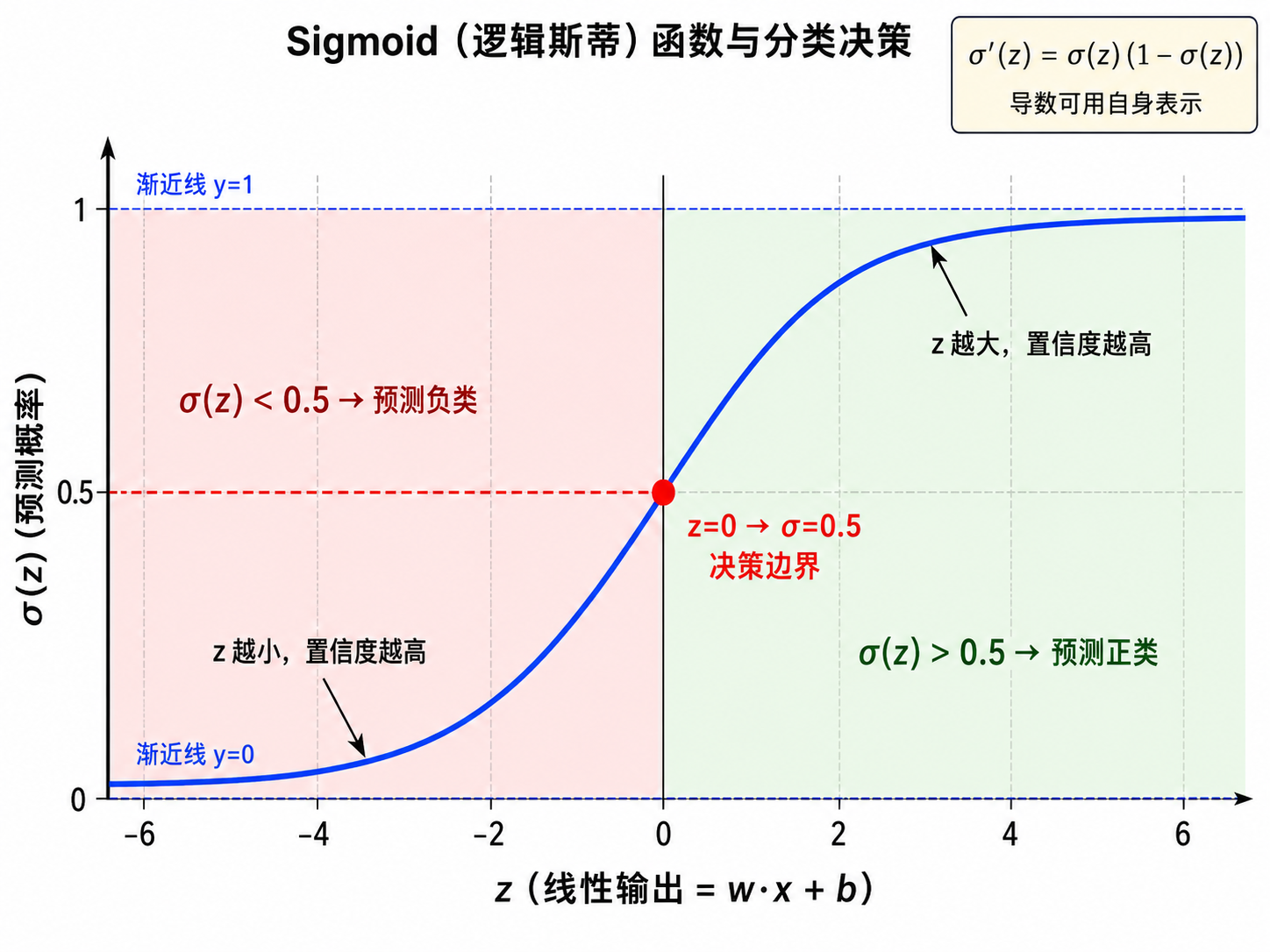
2. Sigmoid 函数:从实数到概率
2.1 定义
Sigmoid 函数(也称 logistic 函数)的定义为:
其中
2.2 关键性质
值域:
对称性:
导数:Sigmoid 的导数可以用自身表示,这是其最重要的数学性质之一:
这个优美的性质使得在反向传播中计算梯度变得异常简单。
中心点:当
2.3 逻辑回归模型
将 Sigmoid 套在线性模型上,就得到了逻辑回归模型:
这个值被解释为「给定输入
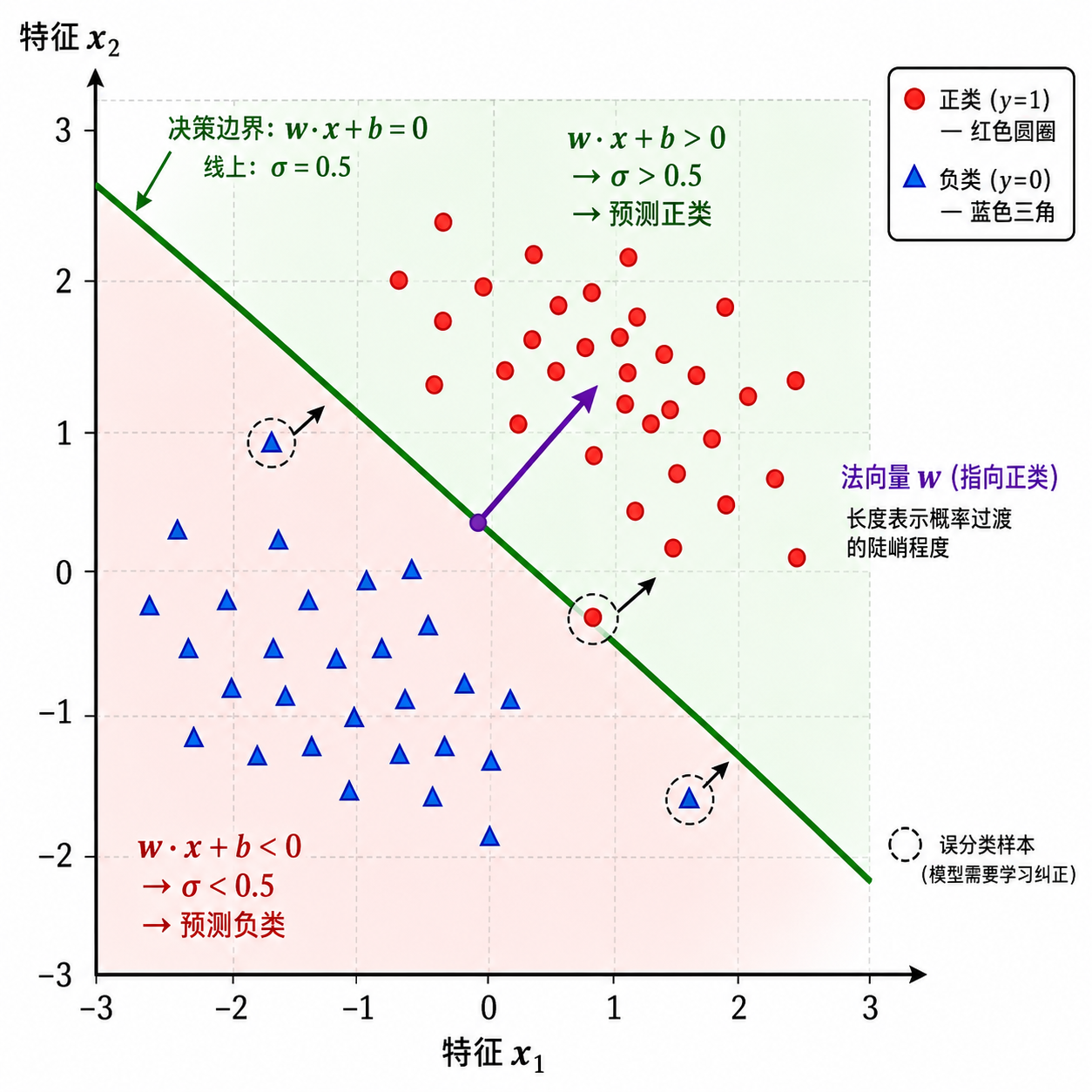
3. 决策边界
逻辑回归输出的是概率,但我们最终需要做出类别决策。规则很简单:
因此,决策边界是满足
几何解释
在二维特征空间中,
- 对于决策边界上方的点,
, ,预测为正类 - 对于决策边界下方的点,
, ,预测为负类
点到决策边界的有符号距离与
4. 交叉熵损失:为什么不用 MSE?
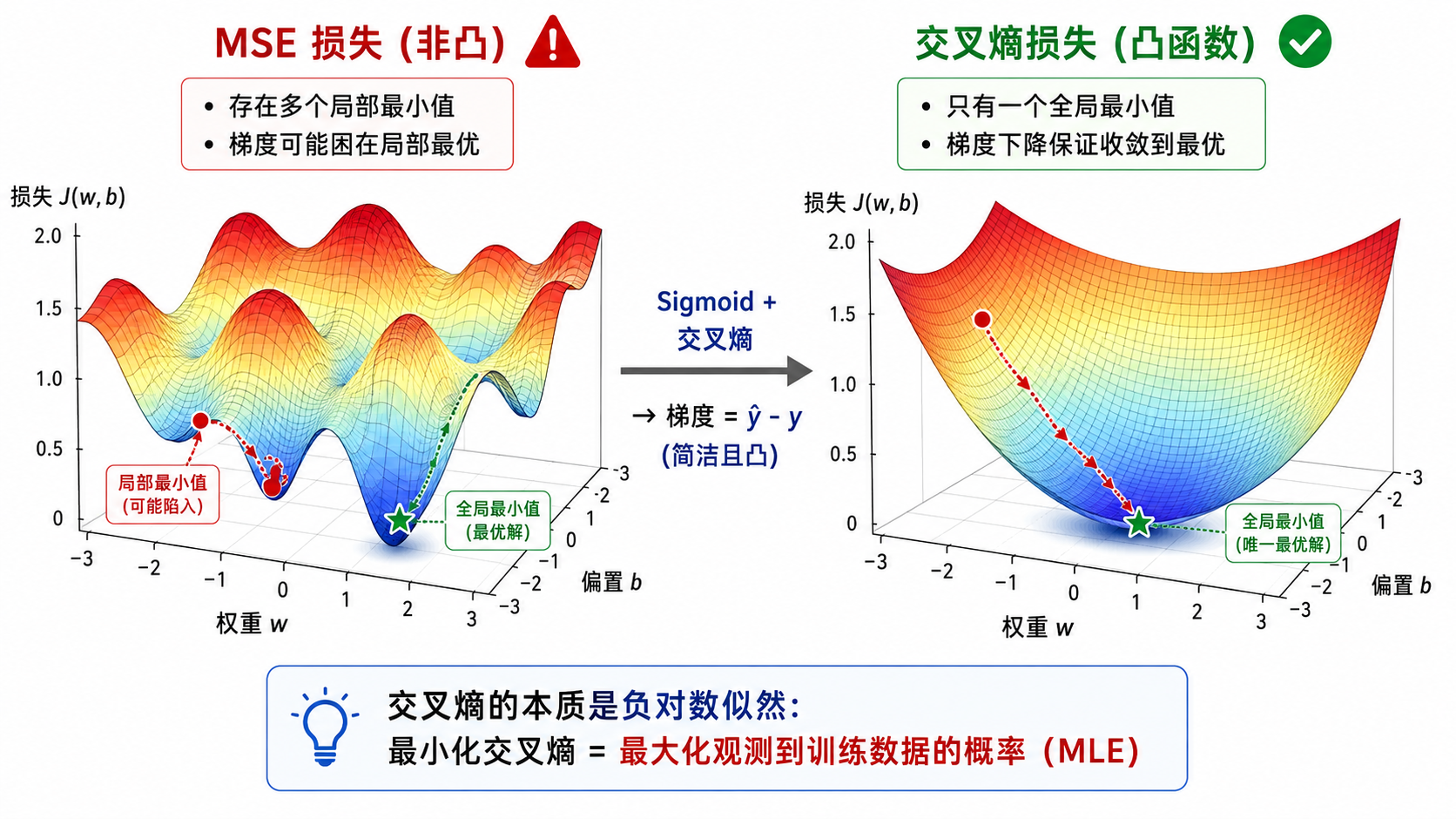
4.1 为什么 MSE 不适合分类
对于二分类问题,如果我们仍使用 MSE 损失:
会遇到一个严重问题:由于 Sigmoid 的「饱和」特性,当预测值接近 0 或 1 且标签相反时,梯度会变得极小(梯度消失),导致训练停滞。更重要的是,MSE 在参数空间中对逻辑回归是非凸的,存在多个局部最小值,梯度下降可能找不到全局最优。
4.2 交叉熵的引入
逻辑回归的标准损失函数是二元交叉熵(Binary Cross-Entropy):
对于
4.3 为什么交叉熵好?
概率解释:交叉熵等价于负对数似然(Negative Log-Likelihood)。最小化交叉熵 = 最大化看到训练数据的概率(MLE)。
梯度优美:交叉熵和 Sigmoid 搭配使用时,梯度中的 Sigmoid 导数项会被约掉,得到一个非常简洁的形式:
这个结果意味着:梯度的方向就是「预测值 - 真实值」,直观合理——预测偏高就往下调,预测偏低就往上调。
凸性:交叉熵损失在参数空间中是凸的(对逻辑回归而言),保证了梯度下降能找到全局最优。
5. 梯度推导
让我们推导逻辑回归 + 交叉熵的完整梯度。
5.1 单样本梯度
对于单个样本
损失对
然后利用链式法则传播到参数:
5.2 批量梯度
对于
你会发现一个惊人的事实:逻辑回归 + 交叉熵的梯度形式与线性回归 + MSE 的梯度形式完全相同(都等于「预测值 - 真实值」乘以输入)!唯一的区别在于
6. 多分类扩展:Softmax 回归
6.1 从二分类到多分类
当有
6.2 Softmax 函数
Softmax 将
它满足:
- 非负性:每个输出
- 归一性:所有输出之和 = 1
- 保序性:如果
,则
![Softmax 函数:将原始得分 [2.0, 1.0, 0.1] 通过 exp 和 normalize 两步变换为概率分布 [0.66, 0.24, 0.10]](/learn-ai/assets/03-04.Bk0kvPzS.png)
6.3 多分类交叉熵
多分类的交叉熵损失(也称 categorical cross-entropy):
其中
梯度同样简洁:
与二分类形式一致!这就是为什么交叉熵 + Sigmoid/Softmax 被称为机器学习中的「黄金搭档」。
6.4 One-vs-Rest 策略
另一种多分类方法是训练
7. 实战案例解析
让我们用一个实例来串联所有概念——使用经典的 Iris 数据集进行花卉分类。
数据准备
Iris 数据集包含 150 个样本,3 个类别(Setosa, Versicolor, Virginica),4 个特征(花萼长度/宽度,花瓣长度/宽度)。为了直观展示,我们通常先取前两个特征做二维可视化。
二分类问题
取其中两个类别(如 Setosa vs Versicolor),训练一个逻辑回归模型。模型会学到一个决策边界直线。
多分类问题
取全部三个类别。我们可以选择:
- Softmax 回归:一个模型输出三个概率
- One-vs-Rest:训练三个二分类器
评估指标
对于分类问题,我们有比 MSE/R² 更合适的指标:
- 准确率(Accuracy):预测正确的比例
- 精确率(Precision):预测为正的样本中,真正为正的比例
- 召回率(Recall):真正的正样本中,被正确预测的比例
- F1-Score:精确率和召回率的调和平均
- 混淆矩阵(Confusion Matrix):直观展示各类别的预测情况
本章总结
逻辑回归虽然名字里带「回归」,但它是最经典的分类模型。它的核心思想简单而优美:
- 用线性模型计算原始得分
- 用 Sigmoid/Softmax 将得分转化为概率
- 用交叉熵损失来度量概率预测的质量
- 用梯度下降(或更高级的优化器)来最小化损失
这个框架——线性变换 + 非线性激活 + 交叉熵损失——是几乎所有现代神经网络的基石。逻辑回归本质上就是一个没有隐藏层的神经网络。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. Chapter 4.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer. Chapter 4.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.