s07 多层网络的矩阵反传
递推公式、mini-batch 平均与完整训练循环 —— 把反向传播扩展到真实的多层网络
一、从标量到矩阵:为什么要用矩阵形式?
在 s06 反向传播与链式法则 中,我们用标量神经元的例子(
对于第
其中:
的形状是 , 是输入维度, 是 batch size 的形状是 的形状是 (通过广播加到每一列) 和 的形状都是
注意:我们使用大写字母(
)表示矩阵,以区别于标量形式。 是输入数据矩阵。
矩阵形式的好处是可以用高效的 BLAS/LAPACK 库(如 NumPy、cuBLAS)来计算,远比逐神经元循环快得多。同时在数学上也更简洁——用几个矩阵公式就能描述整个网络的梯度流。
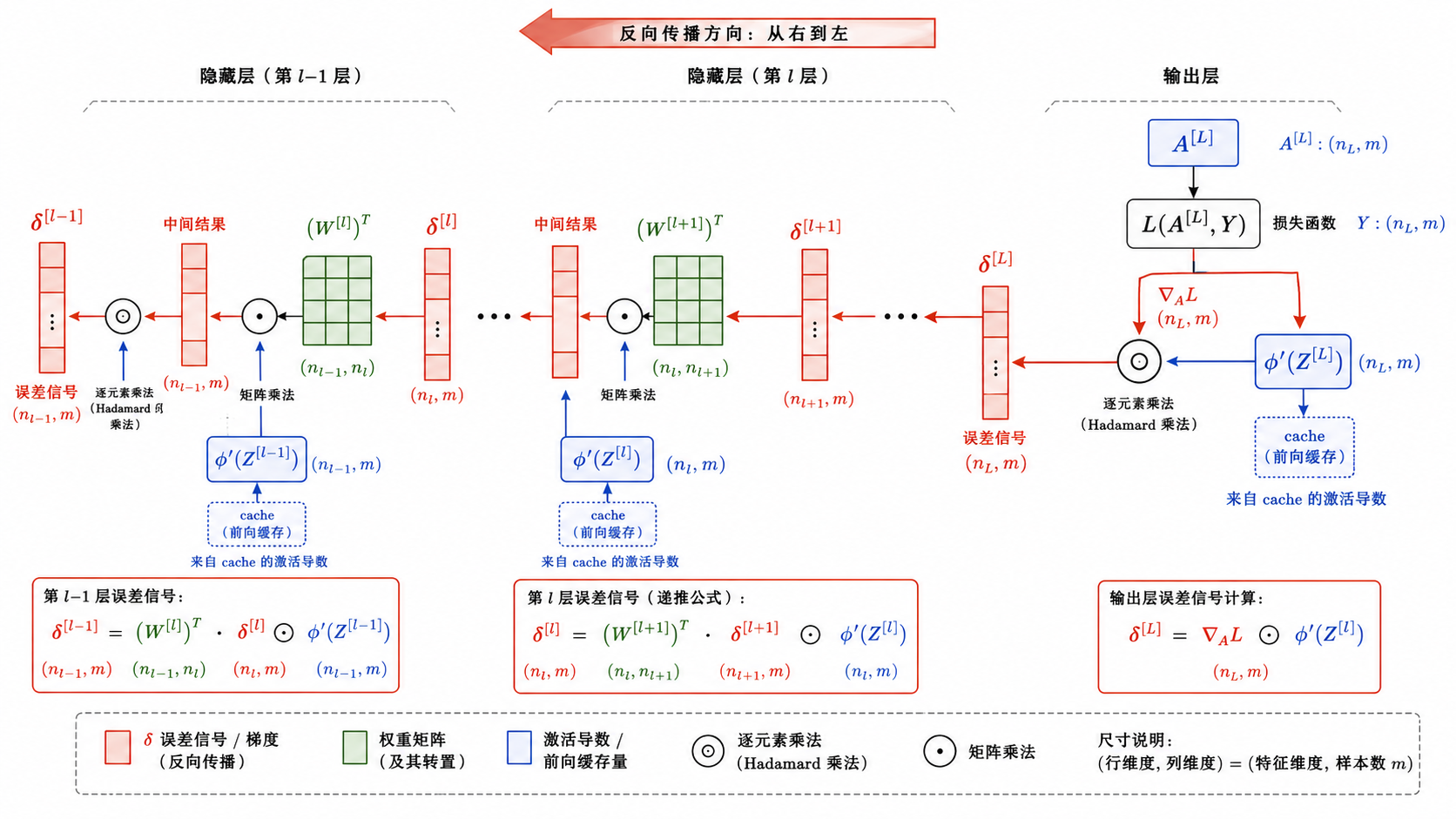
二、
在矩阵形式中,我们引入一个极其重要的中间量——
为什么引入
三、输出层的
反向传播从输出层开始。对于最后一层
通用公式:
其中
常见损失函数的
MSE 损失(回归):
二元交叉熵(二分类,配合 sigmoid 输出):
重要:当输出层同时使用 sigmoid 激活和二元交叉熵损失时,
有一个极其简洁的形式: 。这是因为 sigmoid 导数中的 和交叉熵梯度中的 恰好约掉。这也是为什么这个组合被广泛使用——梯度形式非常干净,训练更稳定。
四、隐藏层的
对于隐藏层(
让我们逐项理解这个公式:
:将第 层的误差信号通过转置的权重矩阵传回第 层。这一步本质上是"责任分配"——"第 层的每个神经元有多少责任,应该追溯到第 层的哪些神经元"。 :第 层激活函数在 处的逐元素导数。这个值在前向传播时已经可以算好(取决于 ),但通常反传时才计算,以节省显存。 (Hadamard 积):逐元素相乘。注意这不是矩阵乘法——是对应位置的元素直接相乘。
维度验证
确保矩阵乘法维度正确,是调试反向传播最重要的技巧之一:
的形状: 的形状: 的形状: 的形状: 的形状: - 最终
的形状:
维度完美匹配。如果你手写反向传播时维度对不上,八成是忘了转置
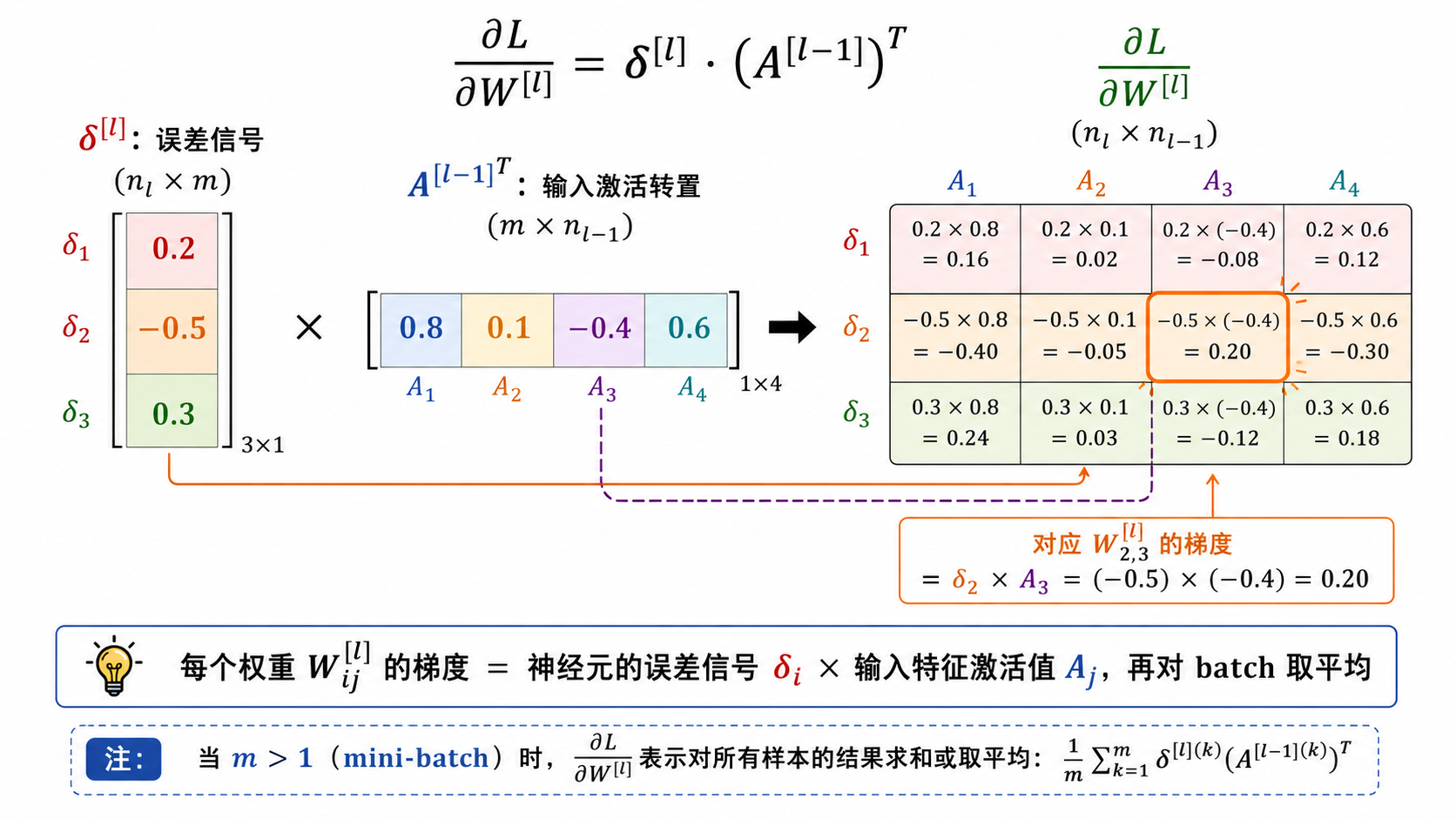
五、参数梯度的计算
有了每层的
权重梯度
这是
的形状: ——每行是该层一个神经元对 个样本的误差信号 的形状: ——每列是第 层一个神经元对 个样本的激活值 - 乘积
的形状: ——与 的形状完全一致
直观理解:
偏置梯度
其中
六、完整的矩阵反向传播伪代码
将以上公式组织成可执行的算法:
输入: 参数 W[1..L], b[1..L]
输入: 一个 mini-batch X (shape: n_in × m), 标签 Y
超参数: 学习率 α
# ============ 前向传播 ============
A[0] = X # 输入层
for l = 1 to L:
Z[l] = W[l] @ A[l-1] + b[l] # 线性变换
A[l] = φ[l](Z[l]) # 激活函数
缓存 Z[l] 和 A[l-1]
Loss = 损失函数(A[L], Y)
# ============ 反向传播 ============
# 输出层
δ[L] = ∇_A L ⊙ φ'[L](Z[L])
# 隐藏层(从后往前)
for l = L-1 downto 1:
δ[l] = (W[l+1])^T @ δ[l+1] ⊙ φ'[l](Z[l])
# 参数梯度
for l = 1 to L:
dW[l] = (1/m) · δ[l] @ (A[l-1])^T
db[l] = (1/m) · sum(δ[l], axis=1)
# ============ 参数更新 ============
for l = 1 to L:
W[l] = W[l] - α · dW[l]
b[l] = b[l] - α · db[l]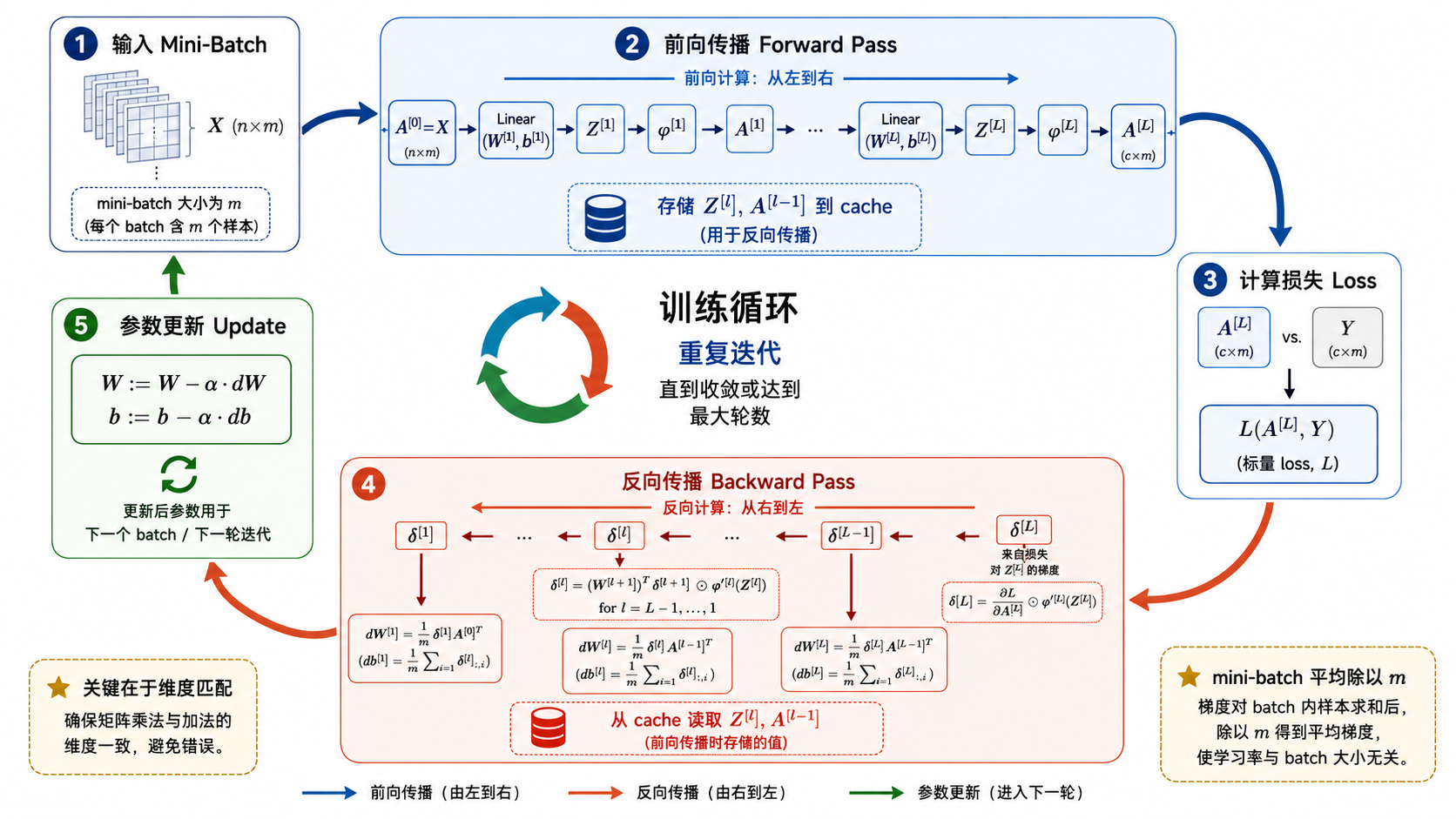
七、梯度检查:用有限差分验证你的实现
手写反向传播最容易出错。梯度检查(Gradient Checking)是一种通过数值方法验证解析梯度的技术。
双边有限差分法
对于一个标量参数
其中
检查步骤
- 对所有参数
做前向传播,然后反向传播算出解析梯度 - 对每个参数,用有限差分法数值估计梯度
- 比较两者的相对误差:
- 相对误差
:实现大概率正确 - 相对误差
:可能有小错误,需要检查 - 相对误差
:几乎肯定有 bug
注意:梯度检查的速度非常慢(每个参数需要两次额外的前向传播),只能在开发调试时用于小网络和少量样本。训练中不要使用。
八、梯度消失与梯度爆炸
从中间层的递推公式可以清楚地看到问题的根源:
梯度在反向传播时,每一步都要乘上权重矩阵的转置和激活函数的导数。经过多层累积后:
梯度消失 (Vanishing Gradient)
当大多数因子的模都小于 1 时,梯度会指数级衰减:
- Sigmoid 和 Tanh 的导数在饱和区接近 0,是梯度消失的主要元凶。
- 早期层的梯度接近零,参数几乎不更新,网络学不到深层特征。
- 症状:前面层的梯度范数远小于后面层,loss 下降极慢。
梯度爆炸 (Gradient Explosion)
当很多因子的模大于 1 时,梯度指数级增长:
- 梯度会迅速增长到极大的值,导致参数更新步长巨大。
- 症状:loss 突然变成 NaN,或者在正常值和极大值之间剧烈震荡。
解决方案一览
| 问题 | 解决方案 |
|---|---|
| Sigmoid/Tanh 饱和 → 梯度消失 | 使用 ReLU 及其变体(导数为 0 或 1,无饱和区) |
| 权重初始化不当 → 梯度消失/爆炸 | He 初始化(ReLU)或 Xavier 初始化(tanh/sigmoid) |
| 深层网络梯度消失 | 残差连接(ResNet)、Batch/Layer Normalization |
| 梯度爆炸 | 梯度裁剪(Gradient Clipping): |
| 两者都有 | 适当的学习率和优化器选择(下一节 s08 详细讨论) |

九、从公式到代码实现
在 code/demo.py 中,我们将实现一个完整的 MLP 类,包含:
__init__:He 初始化权重矩阵,零初始化偏置forward:逐层前向传播,将所有和 存入 cache backward:从出发,依次计算 、 、 update:用计算出的梯度更新所有参数
关键实现细节:
前向传播 cache
# 每层的 cache 存储:
cache = {
"Z": Z, # 用于计算 φ'(Z)
"A_prev": A_prev, # 用于计算 dW = δ @ A_prev^T
}反向传播中的维度匹配
# 隐藏层的 δ 递推
dZ = (W_next.T @ dZ_next) * activation_derivative(Z)
# ^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^
# (n[l], n[l+1]) @ (n[l+1], m) (n[l], m)
# 形状: (n[l], m) 形状: (n[l], m)
# 逐元素相乘 → (n[l], m) ✓
# 权重梯度
dW = dZ @ A_prev.T / m
# ^^^^^^^^^^^^^^^
# (n[l], m) @ (m, n[l-1]) = (n[l], n[l-1]) ✓十、本节小结
| 概念 | 一句话 |
|---|---|
| 损失对第 | |
| 权重梯度 | |
| 偏置梯度 | |
| 梯度检查 | 用有限差分验证解析梯度——开发时的重要调试手段 |
| 梯度消失/爆炸 | 深层网络中梯度的两种极端行为——初始化、激活函数和结构设计共同影响 |
下一节 s08 优化器:从 SGD 到 Adam 将开始讨论"有了梯度之后怎么更新"——为什么朴素 SGD 不够好,以及 Momentum、RMSProp 和 Adam 分别解决了什么问题。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |