algo13 字符串算法
从暴力匹配到 KMP、Trie、AC 自动机、Manacher、后缀数组——字符串处理的核心技术与数据结构
一、字符串匹配基础
1.1 问题定义
给定文本串
1.2 暴力匹配(Brute Force)
对
T = "ABABCABAB"
P = "ABAB"
比较位置 0: ABAB vs ABAB ✓ → 匹配位置 0
比较位置 1: BABC vs ABAB ✗
...
比较位置 5: ABAB vs ABAB ✓ → 匹配位置 5二、KMP 算法
2.1 核心思想
KMP(Knuth-Morris-Pratt)利用已经匹配的部分信息来避免回溯。当匹配失败时,不是回到下一个起始位置,而是利用已匹配前缀的信息直接"跳跃"。
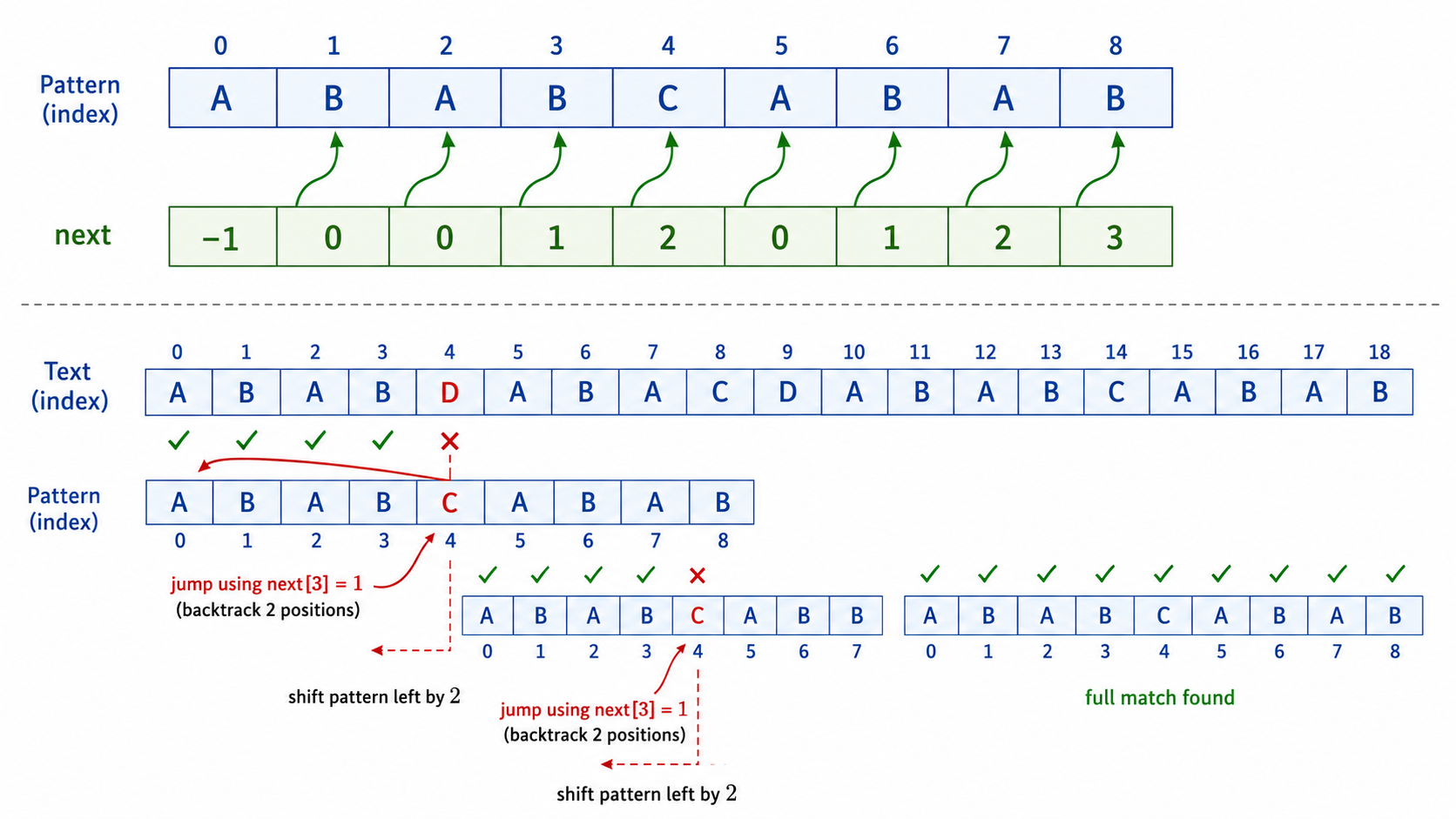
关键数据结构:next 数组(或 failure function / pi 数组)
模式串 P = "ABABCABAB"
索引: 0 1 2 3 4 5 6 7 8
P: A B A B C A B A B
next: -1 0 0 1 2 0 1 2 3
例如 next[3] = 1: "ABAB" 的最长相等前后缀是 "A"(前缀A=后缀A, 但完整的前缀AB≠后缀AB)
next[8] = 3: "ABABCABAB" 的最长相等前后缀是 "ABAB"2.2 next 数组的计算
next 数组本身也是通过类似 KMP 的自匹配过程(模式串对自身匹配)来计算的。复杂度
def compute_next(pattern):
m = len(pattern)
next_arr = [-1] * m
k = -1 # k 表示当前匹配了的前缀的末尾索引
for q in range(1, m):
while k >= 0 and pattern[k + 1] != pattern[q]:
k = next_arr[k] # 回退
if pattern[k + 1] == pattern[q]:
k += 1
next_arr[q] = k
return next_arr2.3 KMP 匹配过程
def kmp_search(text, pattern):
n, m = len(text), len(pattern)
if m == 0: return [0]
next_arr = compute_next(pattern)
matches = []
k = -1 # 已匹配的模式串长度 - 1
for i in range(n):
while k >= 0 and pattern[k + 1] != text[i]:
k = next_arr[k] # 关键:利用 next 跳过不必要的比较
if pattern[k + 1] == text[i]:
k += 1
if k == m - 1: # 完全匹配
matches.append(i - m + 1)
k = next_arr[k] # 继续寻找下一个匹配
return matches总复杂度:
三、Trie(前缀树/字典树)
3.1 基本操作
Trie 是一种多叉树,每个节点代表一个前缀,节点的出边代表下一个字符。
| 操作 | 描述 | 复杂度 |
|---|---|---|
insert(word) | 沿字符边走,不存在则创建节点 | $O( |
search(word) | 检查是否完整单词 | $O( |
starts_with(prefix) | 检查是否有以 prefix 为前缀的单词 | $O( |
3.2 Trie 的结构
插入 "cat", "car", "dog", "door" 后:
root
/ | \
c d ...
/ \
a o
/ \ / \
t* r* g* o
\
r*
(* = 单词结束标记)3.3 应用场景
- 自动补全(Auto-complete):输入前缀,返回所有以该前缀开头的单词
- 拼写检查:快速验证单词是否在字典中
- IP 路由最长前缀匹配
- 异或最大值:将数字按位插入 Trie,查询时尽量走相反的位
四、AC 自动机(Aho-Corasick)
4.1 核心思想
AC 自动机 = Trie + KMP 的失败指针。用于在一个文本串中同时匹配多个模式串。
构建三个步骤:
- 将所有模式串插入 Trie
- 构建失败指针(failure links)——BFS 遍历
- 在文本串上走自动机,每当走到一个节点,沿着 failure 链收集所有匹配
4.2 失败指针
失败指针 fail[u] 指向 Trie 中节点
BFS 构建规则:
- 根节点的直系子节点的 fail 指向根
- 对于节点
的子节点 (对应字符 ),沿着 链寻找第一个也有字符 出边的节点, 指向那个 子节点
复杂度:构建
五、Manacher 算法
5.1 最长回文子串
Manacher 提出了一种
- 插入分隔符:在每个字符间插入
#,统一处理奇偶长度 - 回文半径数组:
R[i]表示以为中心的最大回文半径 - 利用对称性:维护当前最右回文边界,对于其内部的中心点,利用回文的镜像关系减少计算
原串: "babad"
扩展: "#b#a#b#a#d#"
各中心回文半径: [0,1,0,3,0,3,0,1,0,1,0]
最长回文子串: "bab" (或 "aba"), 长度 3复杂度:
六、后缀数组与 LCP
6.1 后缀数组
后缀数组(Suffix Array) 是字符串所有后缀按字典序排序后的起始位置数组。
S = "banana"
后缀:
0: banana
1: anana
2: nana
3: ana
4: na
5: a
排序后:
5: a, 3: ana, 1: anana, 0: banana, 4: na, 2: nana
SA = [5, 3, 1, 0, 4, 2]倍增法(Doubling):通过
6.2 LCP 数组
LCP(Longest Common Prefix)数组:
Kasai 算法可在
七、滚动哈希(Rabin-Karp)
7.1 多项式哈希
将字符串视为一个以
常用参数:
7.2 滚动哈希
通过前缀哈希可以
这为
7.3 Rabin-Karp 字符串匹配
用滚动哈希在
本章总结
| 算法 | 用途 | 复杂度 |
|---|---|---|
| 暴力匹配 | 单模式匹配 | |
| KMP | 单模式匹配(不回退) | |
| Trie | 多字符串集合的前缀操作 | 插入/查询 |
| AC 自动机 | 多模式匹配 | 构建 |
| Manacher | 最长回文子串 | |
| 后缀数组 | 后缀排序、子串问题 | |
| 滚动哈希 | 预处理 | |
| Rabin-Karp | 字符串匹配(哈希版) |
字符串算法是算法竞赛中出镜率最高的类别之一。KMP 的"失败函数"思想(利用已处理信息避免重复计算)是整个领域的核心 intuition——Trie 中的失败指针、Manacher 中的镜像扩展、后缀数组的倍增,都体现了"用空间换时间,用已计算信息加速未计算部分"的哲学。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Knuth, D. E., Morris, J. H., & Pratt, V. R. (1977). Fast Pattern Matching in Strings. SIAM Journal on Computing, 6(2), 323-350. [doi:10.1137/0206024]
- Aho, A. V. & Corasick, M. J. (1975). Efficient string matching: an aid to bibliographic search. Communications of the ACM, 18(6), 333-340.
- Manacher, G. (1975). A New Linear-Time "On-Line" Algorithm for Finding the Smallest Initial Palindrome of a String. Journal of the ACM, 22(3), 346-351.
- Karp, R. M. & Rabin, M. O. (1987). Efficient randomized pattern-matching algorithms. IBM Journal of Research and Development, 31(2), 249-260.