ml14 核方法与高斯过程
从核技巧到高斯过程——当线性模型穿上"核"的外衣,它们获得了拟合非线性函数的能力。而高斯过程则更进一步,直接在函数空间上定义概率分布,给出预测的同时也给出了不确定性。
一、核方法回顾:从线性到非线性
1.1 核技巧(Kernel Trick)
核方法的核心思想:将数据映射到高维(甚至无限维)特征空间,然后在这个空间中做线性模型,但通过核函数避免显式计算高维特征。
给定特征映射
核技巧的关键洞察:许多线性算法只需要计算样本间的内积
直觉:核函数就像"相似度评分"——不需要知道数据在高维空间中的精确坐标,只需要知道"这两个点在高维空间中多相似"就够了。
1.2 Mercer 定理
不是任意函数都可以作为核函数。Mercer 定理给出了充要条件:
一个对称函数
这个条件虽在实际中不常直接验证,但它保证了核函数背后确实存在一个内积空间。
1.3 表示定理(Representer Theorem)
表示定理是核方法的一个深刻结论:很多核化的正则化风险最小化问题的解可以表示为训练数据的核函数线性组合:
这意味着:无论特征空间多大(甚至无限维),最优解始终落在由训练数据张成的有限维子空间内。这是核方法之所以实用的理论基础——我们不需要在无限维空间中搜索,只需优化
1.4 核岭回归(Kernel Ridge Regression)
岭回归的线性版本:
闭式解为
核化后的解(利用表示定理):
其中:
:训练数据的核矩阵( ) :测试点与所有训练点的核函数值
核岭回归的计算复杂度为
二、高斯过程:从权重视角到函数视角
2.1 权重视角(Weight-Space View)
回顾贝叶斯线性回归:
由于
2.2 函数空间视角(Function-Space View)
高斯过程(Gaussian Process, GP)绕过权重,直接在函数空间上定义先验:
一个高斯过程由均值函数
对任意有限点集
函数视角的优雅之处:我们不定义
的先验然后推导 的分布;我们直接定义 本身是一个随机函数——它的任何有限维投影都是多元正态分布。GP 是"函数的分布"。
![GP 先验示意图:x 轴范围 [-5, 5],y 轴无数据。灰色阴影表示 ±2σ 置信带(恒定宽度),三条彩色曲线是从 GP 先验中采样的随机函数(RBF 核,lengthscale=1.0)。标注:"GP Prior ~ N(0, K),均值=0,不确定性恒为 σ²"](/learn-ai/assets/ml14-01-gp-prior.Dw-EBbLE.png)
2.3 高斯过程回归(GP Regression)
给定训练数据
先验:
似然(高斯噪声):
后验预测(对新点
其中:
关键观察:
- 预测均值和核岭回归的闭式解完全一致——GP 回归从概率视角给出了同一公式的推导
- 预测方差有两项:先验方差
减去训练数据带来的不确定性缩减 - 不确定性在数据密集区域小、稀疏区域大——这正是 GP 最吸引人的特性
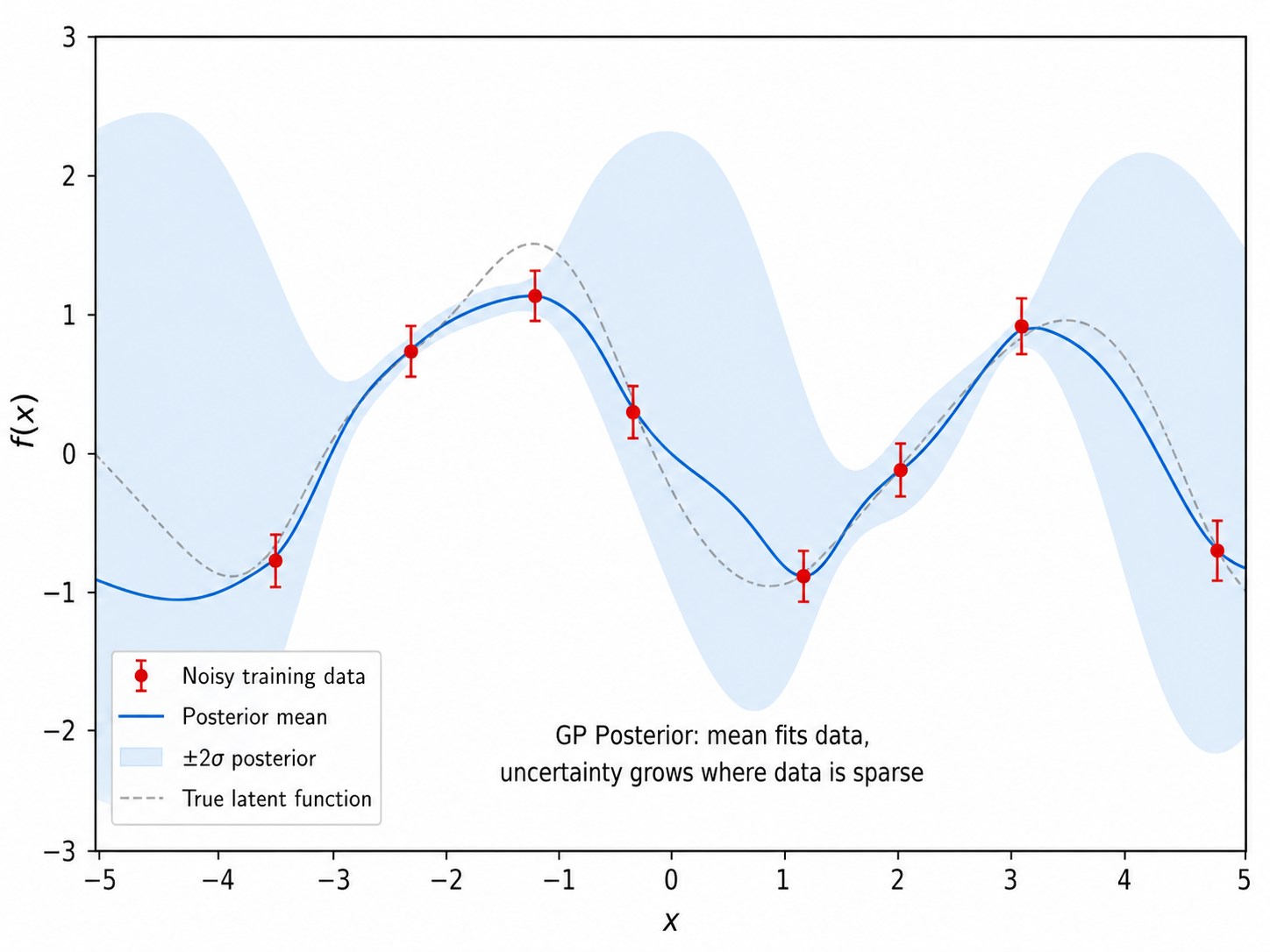
三、核函数的选择
核函数是 GP 的核心——它编码了我们对函数平滑性、周期性等性质的先验假设。
3.1 RBF(径向基 / 高斯核 / squared exponential)
(lengthscale):控制函数的"摆动"频率。 小 → 函数快速变化; 大 → 函数平滑 (signal variance):控制函数的整体振幅 - 特性:无限阶可导(函数极其平滑),是 GP 的默认核
3.2 Matern 核
其中
:等价于指数核(Ornstein-Uhlenbeck 过程),函数连续但不可导 :一阶可导 :二阶可导(实践中常用,比 RBF 略微粗糙但更稳健) :等价于 RBF
Matern 核对 RBF 的改进:RBF 假设函数无限光滑,这在很多真实场景中过于理想化。Matern 核通过
3.3 周期核(Periodic Kernel)
用于建模具有周期性的函数(如季节性时间序列)。
3.4 核的组合
核函数可以像积木一样组合:
- 加法
:函数是 (长期趋势 + 短期波动) - 乘法
:函数是 (调制) - 这些组合允许 GP 建模复杂结构(如
用于"带趋势的季节性")
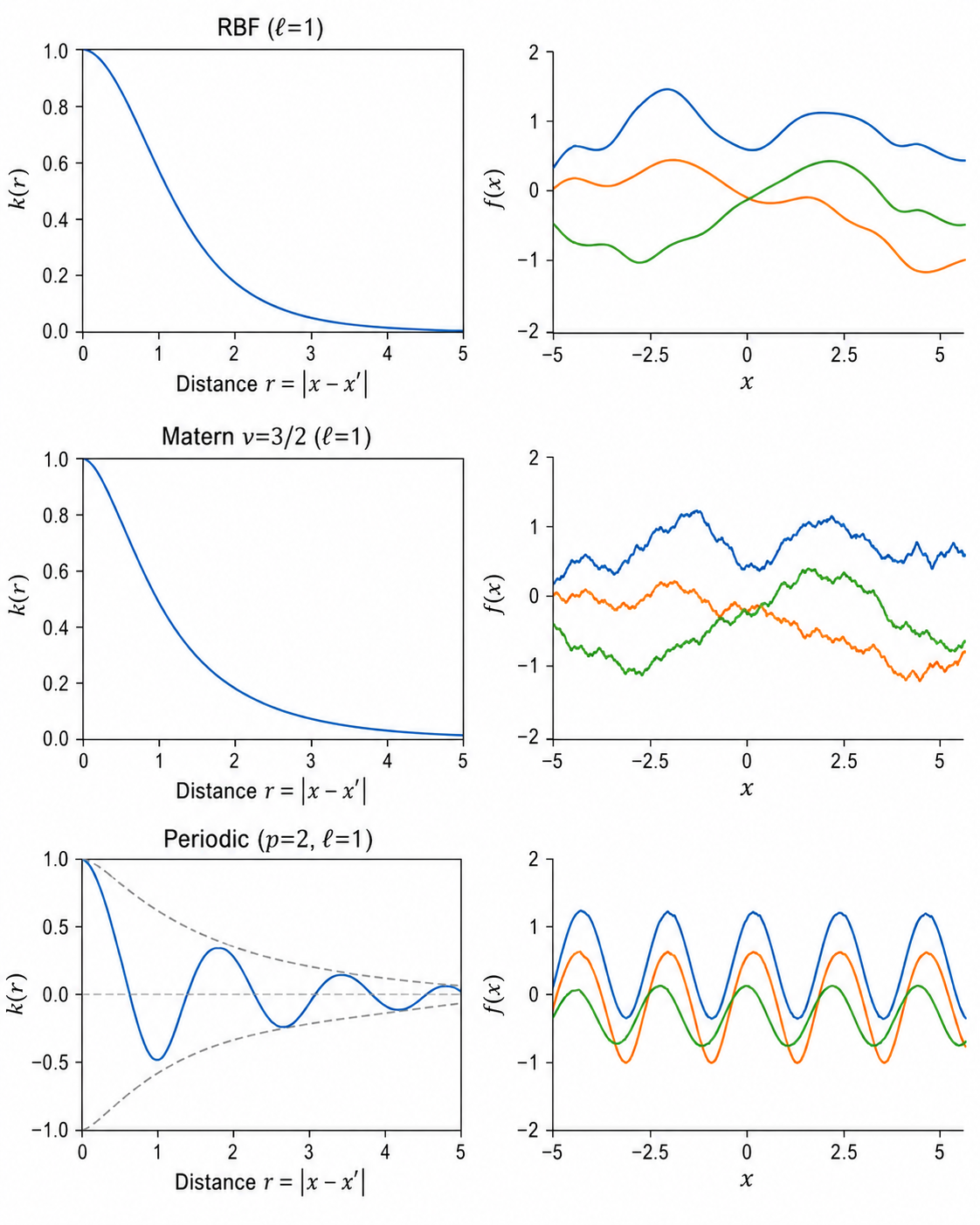
四、GP 的模型选择
4.1 超参数学习
GP 的超参数(如 RBF 的
三项的直觉:
- 数据拟合项:
—— 衡量模型对数据的拟合程度 - 复杂度惩罚项:
—— 自动惩罚过于复杂的核(过拟合的多余复杂度) - 归一化常数:
GP 的优雅之处:GP 不需要交叉验证来选择超参数——边际似然自然地平衡了拟合度和模型复杂度。这一性质源自贝叶斯框架的"奥卡姆剃刀"。
4.2 GP 的计算局限
GP 的标准实现需要
- 稀疏 GP(Sparse GP):用
个诱导点(inducing points)近似,复杂度 - 随机傅里叶特征(RFF):用有限维特征近似核函数
- 分治策略:将数据分区,在各区独立做 GP 后再融合
五、GP 与其他方法的联系
| 方法 | 联系 |
|---|---|
| 核岭回归 | GP 回归的预测均值 = 核岭回归解(点估计) |
| 贝叶斯线性回归 | |
| 神经网络 | 无限宽神经网络的输出收敛到 GP(NNGP) |
| Kriging | 地统计学中 GP 回归的别名(同名不同领域) |
| Smoothing Splines | 一维 GP with 特定核的特殊情况 |
本章总结
| 概念 | 一句话 |
|---|---|
| 核技巧 | |
| Mercer 定理 | Gram 矩阵半正定 |
| 表示定理 | 最优解 = 训练数据的核函数线性组合 |
| 核岭回归 | |
| 高斯过程 | 函数上的概率分布: |
| GP 先验 | 没有数据时对函数的先验信念(平滑性、周期性等) |
| GP 后验 | 结合数据后对函数的更新信念(均值 + 置信带) |
| 预测不确定性 | 数据点附近窄(高置信),远离数据时宽(低置信) |
| RBF 核 | |
| Matern 核 | 通过 |
| 边际似然 | $\log p(\mathbf |
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Rasmussen, C. E. & Williams, C. K. I. (2006). Gaussian Processes for Machine Learning. MIT Press. [web]
- Scholkopf, B. & Smola, A. J. (2002). Learning with Kernels. MIT Press. [ISBN:978-0262194754]
- Mercer, J. (1909). Functions of Positive and Negative Type, and their Connection with the Theory of Integral Equations. Phil. Trans. Royal Society A, 209, 415-446. [doi:10.1098/rsta.1909.0016]
- Kimeldorf, G. S. & Wahba, G. (1970). A Correspondence Between Bayesian Estimation on Stochastic Processes and Smoothing by Splines. The Annals of Mathematical Statistics, 41(2), 495-502. [doi:10.1214/aoms/1177697089]
- Neal, R. M. (1996). Bayesian Learning for Neural Networks. Springer. (NNGP 源头) [doi:10.1007/978-1-4612-0745-0]