支持向量机 (SVM)
1. 最大间隔分类器
1.1 线性可分情况下的直觉
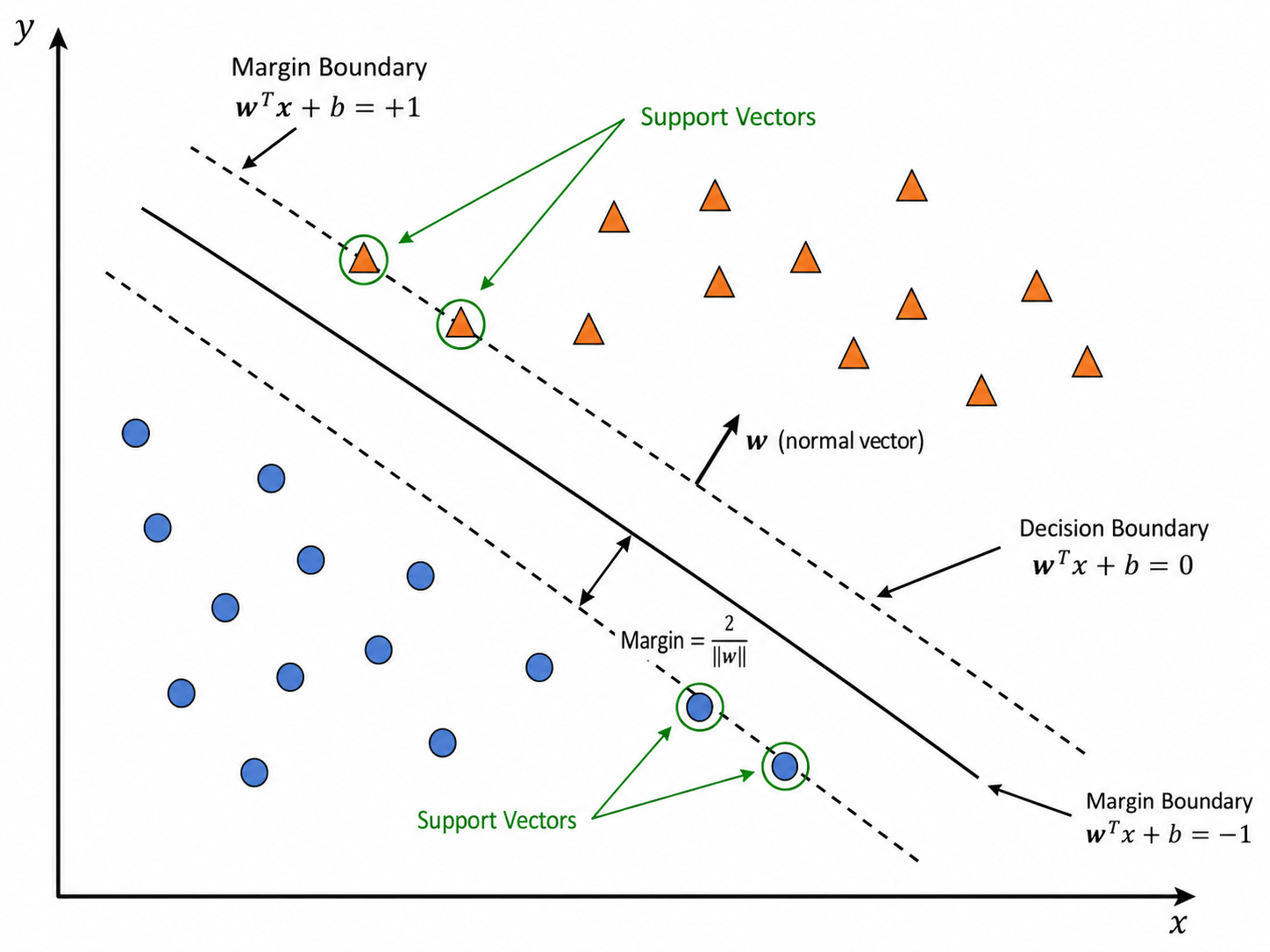
支持向量机(Support Vector Machine, SVM)的核心思想是:在能正确分类的所有超平面中,找一个离两类数据都"最远"的超平面。
对于线性可分数据集,存在无穷多个分类超平面。但哪个是最好的?SVM 的答案是:最大化**间隔(margin)**的那个。
数学上,分类超平面定义为:
其中
将正类标签设为
1.2 硬间隔 SVM 的优化问题
几何间隔(Geometric Margin)定义为所有样本点到超平面的最小距离:
SVM 的目标是最大化这个最小间隔:
约束条件
等价地,可以写成更常见的凸二次规划形式:
1.3 对偶问题与 KKT 条件(几何直觉)
通过拉格朗日乘子法,原始问题可以转换为对偶问题。引入拉格朗日乘子
对
代入拉格朗日函数,得到对偶问题:
KKT 互补松弛条件告诉我们:
- 若
:样本 不是支持向量,不影响决策 - 若
:样本 是支持向量,满足
这就是"支持向量机"名字的由来——决策只由少数支持向量决定,与其他样本无关。
为什么使用对偶形式?
- 对偶问题中样本仅以内积
的形式出现——这为核技巧(Kernel Trick)打开了大门 - 对偶问题的变量数 =
(样本数),原始问题的变量数 = (特征维数)。当 时,对偶问题更高效
2. 软间隔 SVM
2.1 松弛变量与惩罚参数 C
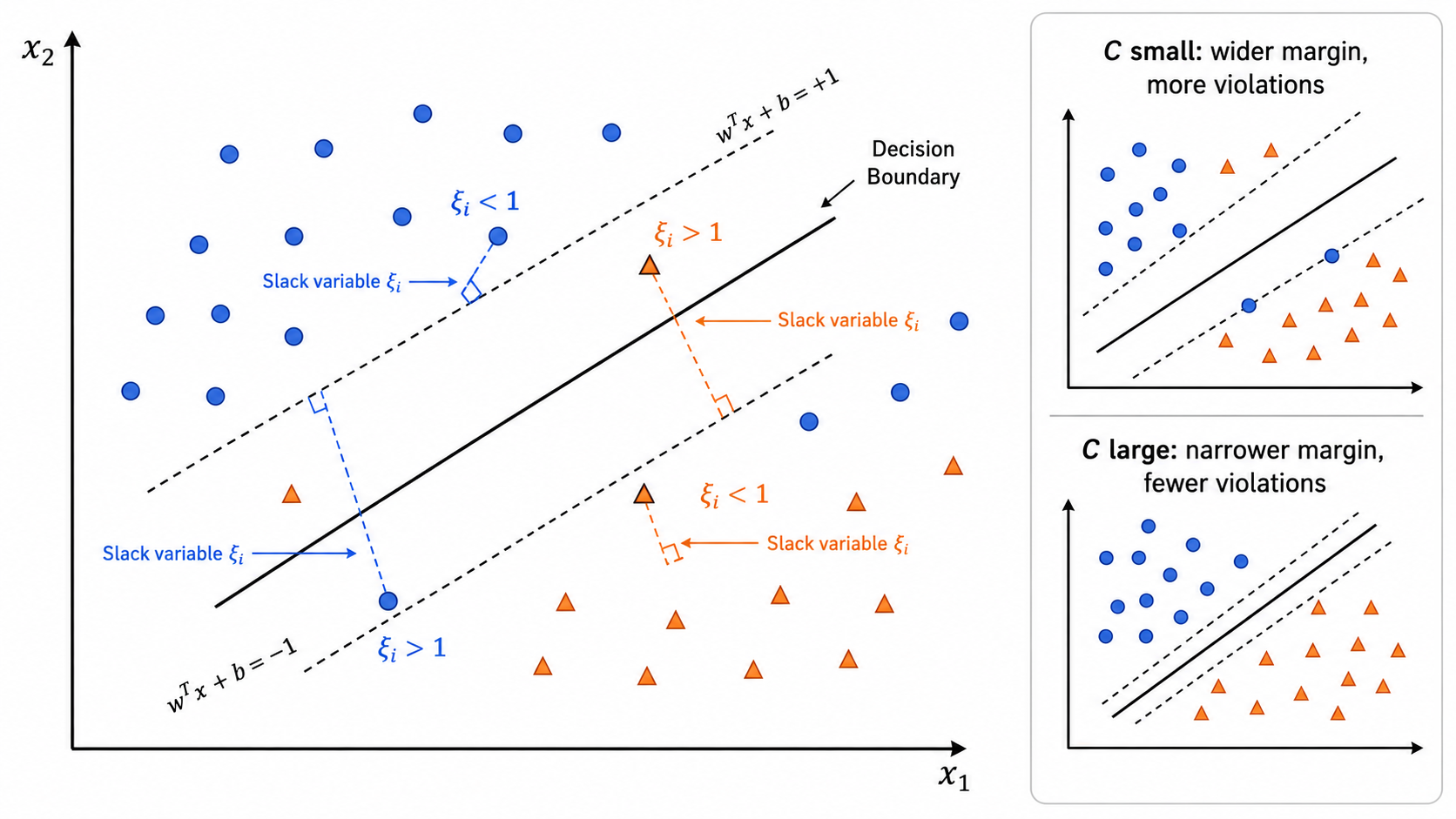
现实数据很少完全线性可分。软间隔 SVM(Soft Margin SVM)允许一些样本违反间隔约束,但对此施加惩罚。
引入松弛变量(Slack Variables)
其中
很大(如 ):对错误的惩罚很重,模型近似硬间隔 SVM,容易过拟合 很小(如 ):允许更多错误,间隔更大,模型更简单
2.2 从 Hinge Loss 角度理解
SVM 的原始问题等价于以下无约束优化问题:
其中
Hinge Loss 的特点:
- 当
(正确分类且超出间隔),损失为 0 - 当
(正确分类但在间隔内),损失为 - 当
(错误分类),损失为 (线性增长)
与 logistic regression 的交叉熵损失相比,Hinge Loss 对"有把握的"正确分类不产生损失,更加稀疏。
这个视角对于使用 SGD 优化 SVM 非常有用——可以直接对 Hinge Loss + L2 正则化做梯度下降,避免了二次规划的复杂性。
3. 核技巧(Kernel Trick)
3.1 动机:线性不可分问题
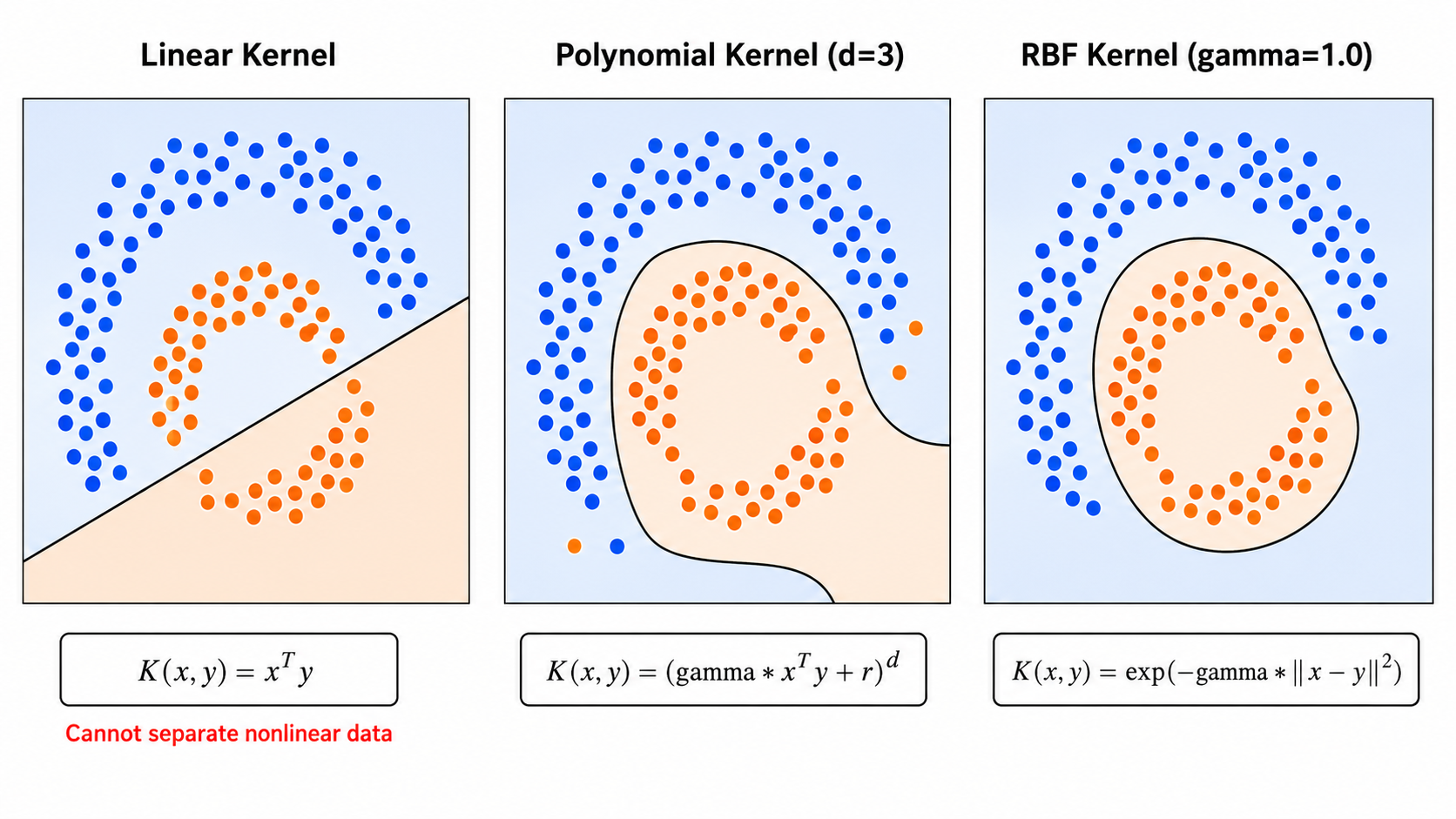
现实中的很多分类问题是非线性可分的(如 XOR 问题、同心圆数据)。一种思路是将数据映射到高维空间,使数据在新空间中线性可分。
例如,原始二维空间中的 XOR 问题在线性 SVM 下无法解决,但映射到
3.2 核函数的定义
核函数
注意 SVM 的对偶形式中,样本仅以
3.3 常用核函数
线性核(Linear Kernel):
不做任何变换,等价于原始的线性 SVM。适用于特征维度高、样本量大的情况(如文本分类)。
多项式核(Polynomial Kernel):
参数
RBF / 高斯核(Radial Basis Function):
最常用的非线性核。参数
大:每个支持向量的影响范围小,决策边界复杂(容易过拟合) 小:影响范围大,决策边界平滑(容易欠拟合)
RBF 核将数据映射到无限维空间(泰勒展开可知),但它极其灵活,几乎可以拟合任何决策边界——前提是选好
核的选择:
| 核函数 | 公式 | 适用场景 | 关键参数 |
|---|---|---|---|
| 线性 | 高维稀疏数据(文本) | — | |
| 多项式 | 已知特征交互阶数 | ||
| RBF | 一般非线性问题(首选) | ||
| Sigmoid | 神经网络类比 |
3.4 Mercer 条件
不是任意二元函数都可以作为核函数。Mercer 定理指出:一个函数
在实践中,常用的核函数(线性、多项式、RBF、Sigmoid)都满足 Mercer 条件,可以放心使用。
4. 从零实现线性 SVM(Hinge Loss + SGD)
4.1 核心思路
使用 Hinge Loss + L2 正则化的形式,通过 SGD 优化:
class LinearSVM:
def fit(self, X, y):
for epoch in range(n_epochs):
for each sample (x_i, y_i):
if y_i * (w^T x_i + b) < 1: # 违反间隔
grad_w = 2 * lambda_ * w - y_i * x_i
grad_b = -y_i
else: # 在间隔外
grad_w = 2 * lambda_ * w
grad_b = 0
w -= lr * grad_w
b -= lr * grad_b4.2 梯度推导
Hinge Loss 对
加上 L2 正则化项:总梯度 =
4.3 支持向量的识别
训练完成后,支持向量可以通过以下条件识别:
margin = y_i * (w^T x_i + b)
sv_mask = (margin >= 0.99) & (margin <= 1.01)
# 或使用对偶变量: alpha_i > 0 的样本在 SGD 方法中,所有满足
本章总结
| 概念 | 公式/描述 | 关键点 |
|---|---|---|
| 最大间隔 | 选择离数据最远的超平面 | |
| 支持向量 | 唯一影响决策的训练样本 | |
| 对偶问题 | 仅以内积形式出现 | |
| KKT 条件 | 支持向量的判定 | |
| 松弛变量 | 允许违反间隔 | |
| 惩罚参数 | ||
| Hinge Loss | SGD 可优化形式 | |
| 核函数 | 隐式高维映射 | |
| RBF 核 | 最常用非线性核,无限维 | |
| Mercer 条件 | Gram 矩阵半正定 | 核函数的合法性判定 |
参考
- Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273-297. DOI: 10.1007/BF00994018
- Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992). A training algorithm for optimal margin classifiers. COLT '92, 144-152. DOI: 10.1145/130385.130401
- Scholkopf, B., & Smola, A. J. (2002). Learning with Kernels. MIT Press. ISBN: 9780262194754
- Burges, C. J. C. (1998). A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery, 2(2), 121-167. DOI: 10.1023/A:1009715923555
- Cristianini, N., & Shawe-Taylor, J. (2000). An Introduction to Support Vector Machines. Cambridge University Press. DOI: 10.1017/CBO9780511801389
- Hsu, C. W., Chang, C. C., & Lin, C. J. (2003). A practical guide to support vector classification. Technical Report, National Taiwan University. Link
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. DOI: 10.1007/978-0-387-45528-0 第 7 章
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer. DOI: 10.1007/978-0-387-84858-7 第 12 章