s06 反向传播与链式法则
每个节点只关心自己的局部导数 —— 揭开 autograd 的魔法
一、核心问题:一个参数的微小变化如何影响损失?
在上一节 s05 计算图与前向传播 中,我们学会了把神经网络组织成计算图,前向地计算预测值和损失。现在来到训练最关键的环节:反向传播。
考虑一个具体的问题。神经网络中有一个权重参数
这个偏导数就是
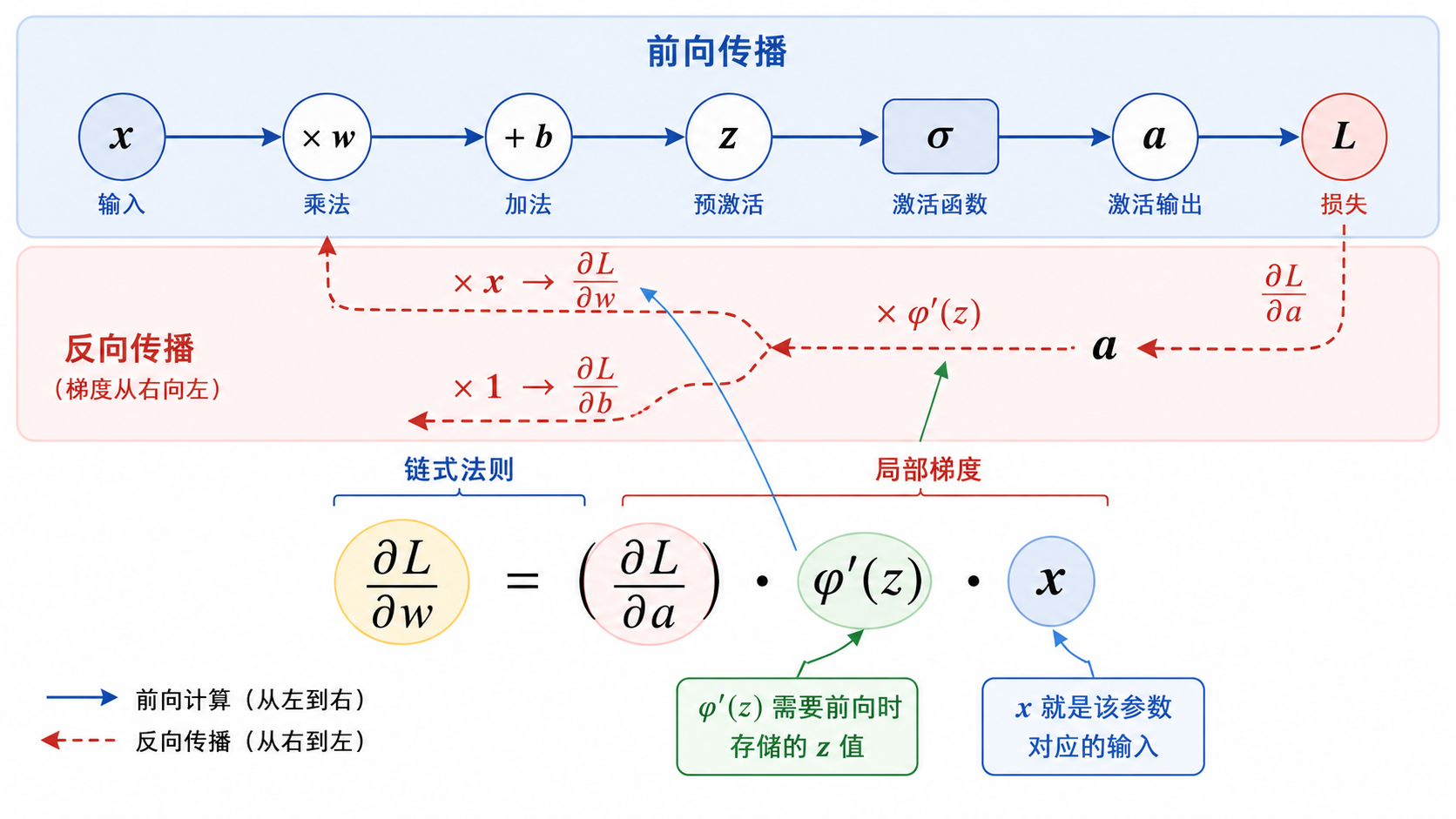
二、链式法则:从简单神经元开始
考虑一个最小化的神经元模型:
我们想知道
逐项拆解:
- 第一项
:损失对激活输出的梯度。对于 MSE 损失 ,这就是 。对于交叉熵,公式会复杂一些,但原理相同。 - 第二项
:激活函数的导数。这一项在 处取值,所以前向传播时必须存储 。 - 第三项
:因为 ,对 求偏导就是 。类似地, 。
把它们乘起来:
对偏置的梯度更简单:
直观理解:
的梯度 = "损失对你的输出有多不满" "激活函数在当前点的斜率" "这个参数对应的输入值的大小"。如果输入 很大,那么 的梯度也大,意味着这个 对最终结果影响大,需要更大的调整。
三、为什么叫"反向"传播?
"反向"是相对于前向传播而言的:
- 前向传播:数据从输入流向输出(
),这是计算预测值的过程。 - 反向传播:梯度从损失流回输入(
),这是计算梯度信息的过程。
反向传播的计算顺序恰好与前向相反。这不是人为规定,而是数学必然——链式法则的每一项都依赖"后面"的计算结果:
- 要算
,需要先知道 和 - 要算
,需要先知道 和
所以算法的自然流程是:先一路前向算到损失,再一路反向把梯度传回去。这也是为什么前向传播时要把中间值都存起来——反向时会逐个用到。
四、计算图视角:每个节点只关心自己
反向传播真正的"魔法"在于:网络再深,每个节点只需要实现自己的局部导数规则。
考虑计算图中的一个乘法节点:
当反向传播时,这个节点收到"上游"传来的梯度
因为
注意一个有趣的现象:乘法门的梯度分配是"交换"的——
再看加法节点:
因为
加法门像是一个"梯度分发器"——上游梯度原样复制给每个输入。这就是为什么在 x += y 操作中,梯度是累积的。
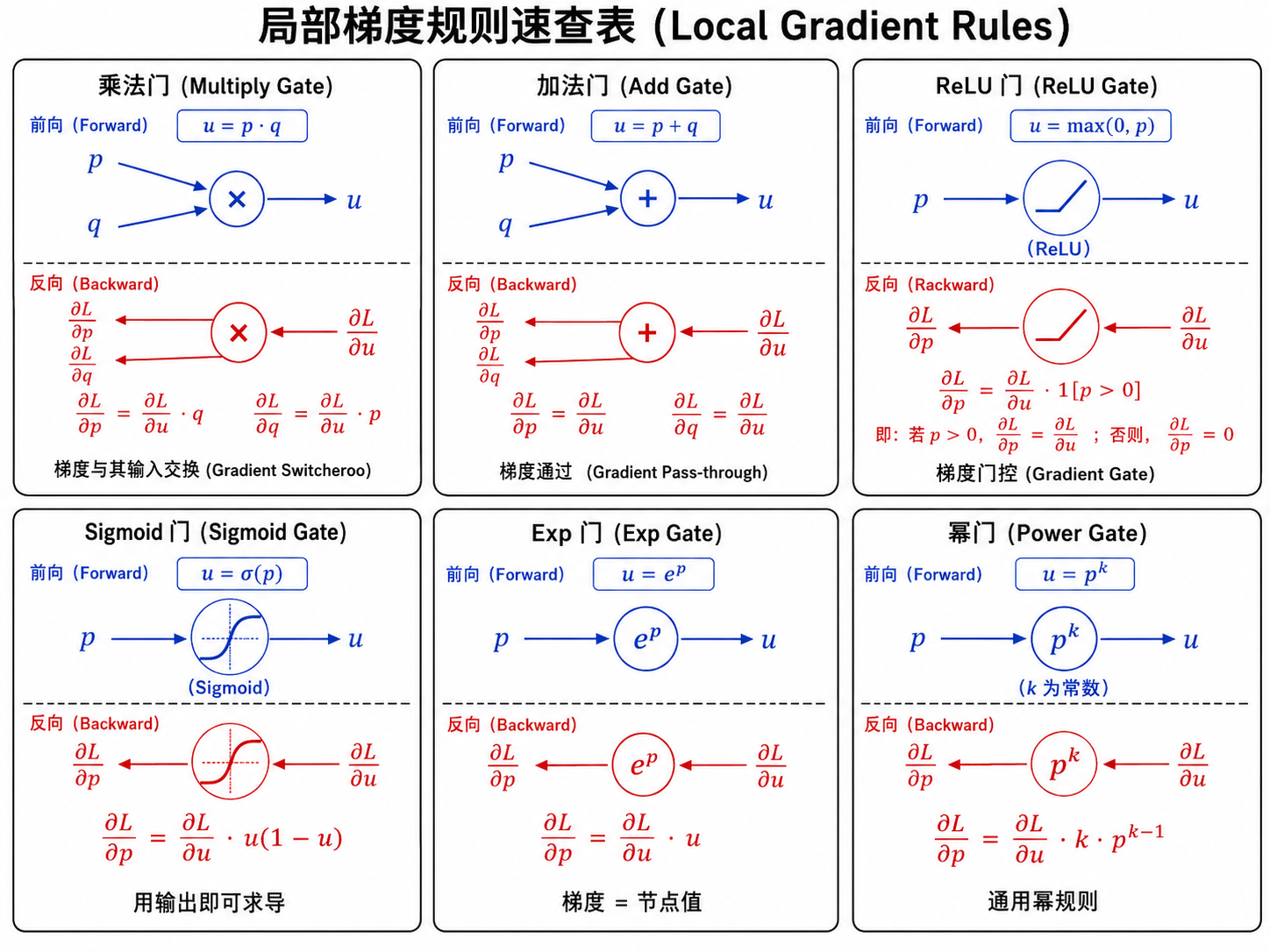
五、常见操作的局部梯度规则
以下是计算图中常见操作的反向传播规则,可以当作参考卡片使用:
| 前向操作 | 局部导数 | 反向规则 |
|---|---|---|
| 梯度原样传递: | ||
| 梯度交换(乘以对方的值) | ||
| 注意 | ||
| 相当于 | ||
| 像一个"门"——根据前向时的 | ||
| 用前向输出即可算出导数,无需知道 | ||
| 同样可以用输出直接算导数 | ||
| 梯度等于自身的值 |
关键思想:每种操作都是独立的"乐高积木"。深度学习框架(PyTorch、TensorFlow、JAX)在底层为每种操作都实现了
forward()和backward()两个函数,然后把它们按计算图拼起来。当你调用.backward()时,框架不过是在按拓扑序的逆序逐个调用这些节点的backward()。
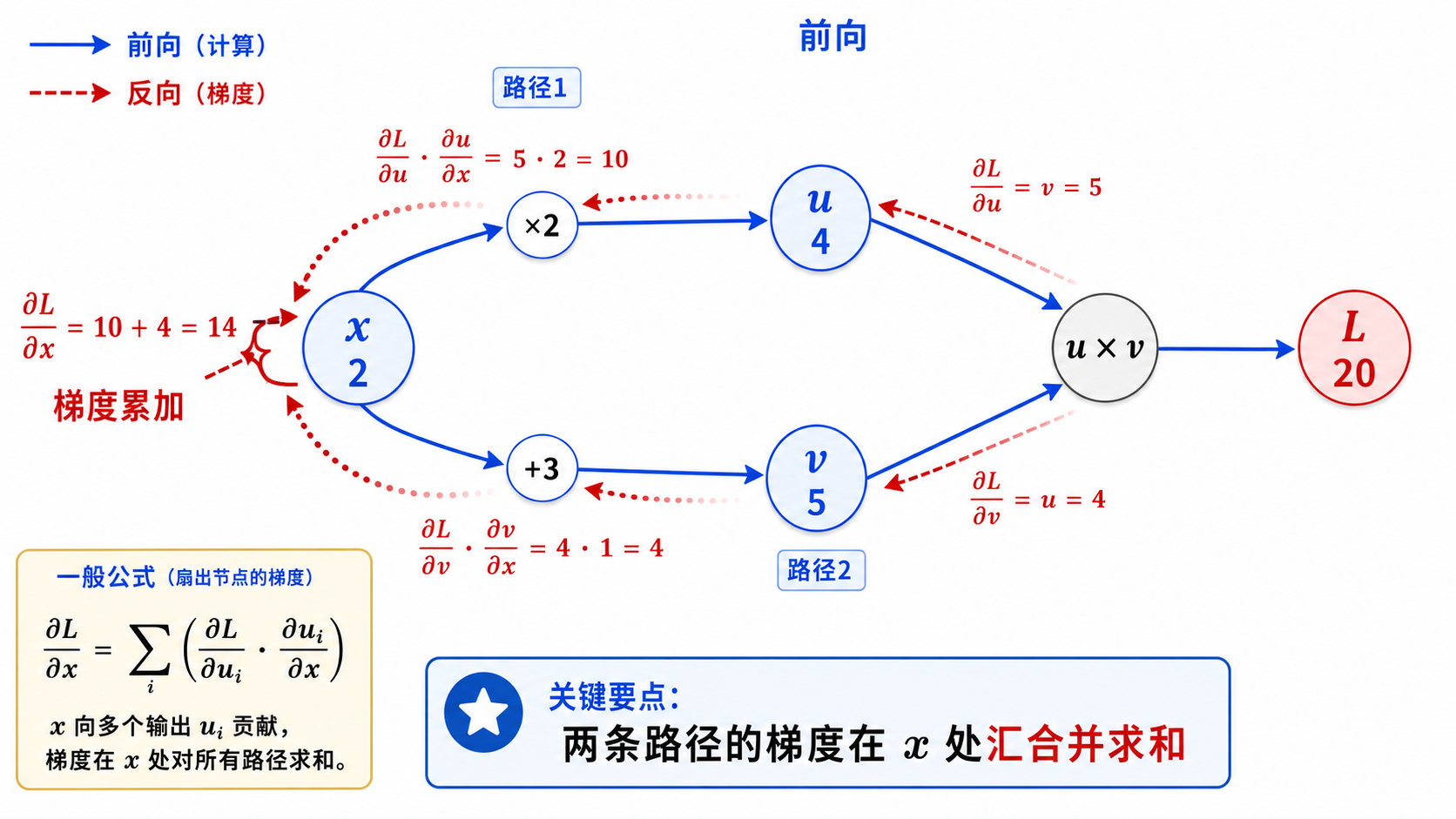
六、梯度累积:多路径的 Fan-Out
一个变量可能在计算图中被多次使用(fan-out)。例如:
x ──┬──→ [×2] ──→ u ──┐
│ ├──→ [u·v] ──→ L
└──→ [+3] ──→ v ──┘这是多元微积分中全导数的链式法则:
其中
在代码实现中,这就是为什么梯度要累加(grad += ...),而不是直接赋值(grad = ...)。PyTorch 中的 .backward() 默认就是累加模式,所以在每次反向传播前需要调用 optimizer.zero_grad() 来清零。
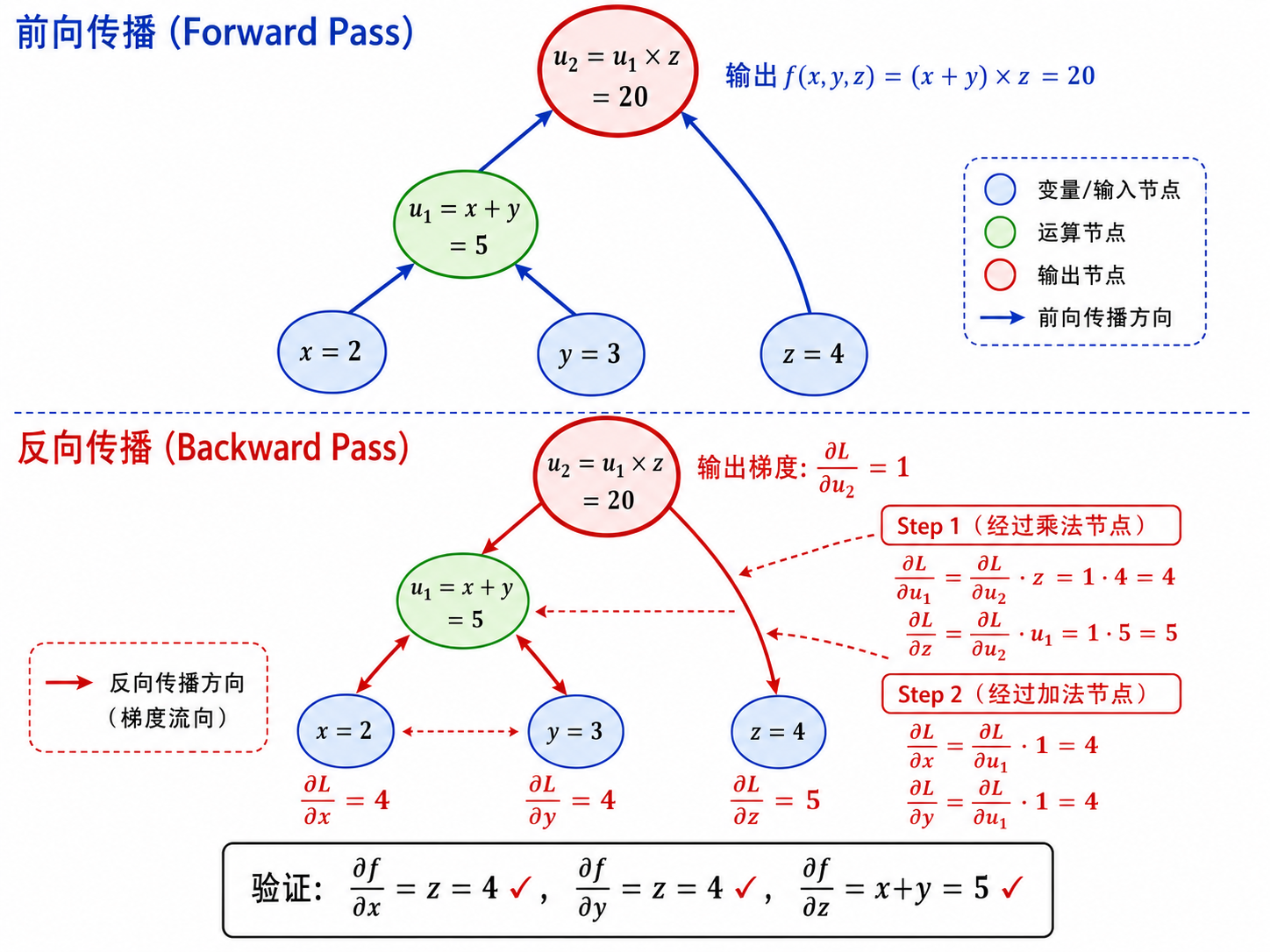
七、完整示例:用手算理解反向传播
让我们通过一个具体例子,手动做一遍前向和反向计算。考虑表达式:
给定具体值:
前向传播(Forward Pass)
所以
反向传播(Backward Pass)
我们要计算
从输出端开始(设
步骤 1:穿过乘法门
步骤 2:穿过加法门
验证
这就是反向传播的全貌——一个具体的、可复现的过程。所有深度学习框架的 backward() 不过是在更大的计算图上做同样的事情。
八、反向传播的复杂度分析
反向传播的一个重要特性是它与前向传播有相同的计算复杂度(量级上)。具体来说:
- 前向传播:遍历一次计算图,每个节点计算一次
- 反向传播:逆向遍历一次计算图,每个节点计算一次
两者都是
空间复杂度则更高,因为反向传播需要存储前向传播的所有中间值。对于有
九、从手动求导到自动微分
人类手动求导的方式是:写出整个函数的符号表达式,然后对每个参数求导。对于浅层网络这还可操作,但面对上千层的网络,写出一个包含百万参数的巨大导数表达式是完全不可能的。
自动微分(Automatic Differentiation, AD)的解决方式是:
- 把复杂函数拆成基本操作(加、减、乘、除、指数、log、sin 等)。
- 为每个基本操作手工实现一个 "局部 backward"——就像我们上面整理的规则卡片。
- 前向计算时,记录操作顺序和中间值。
- 反向时,按逆序依次调用每个操作的 backward。
这种方法叫做反向模式自动微分(Reverse-mode AD),是深度学习框架的核心引擎。它的关键优势是:不管函数多复杂,只要它能被分解为基本操作,就能自动求出所有参数的梯度——而且计算量和前向是同量级的。
下一节 s07 多层网络的矩阵反传 将在矩阵层面推导完整的反向传播公式(包括
递推关系),并实现一个完整的训练循环。
十、本节小结
| 概念 | 一句话 |
|---|---|
| 链式法则 | 将间接依赖的梯度拆成局部导数连乘 |
| 反向顺序 | 从损失往回算,自然地对应链式法则的计算顺序 |
| 局部梯度 | 每个节点只需知道自己的导数规则,不关心网络其他部分 |
| 梯度累积 | 当一个变量有多条输出路径时,梯度要求和 |
| 自动微分 | 框架记录前向操作图,反向时自动逐节点传梯度 |
| 复杂度 | 前向和反向都是 |
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature. [doi:10.1038/323533a0]
- LeCun, Y., Bottou, L., Orr, G. B., & Müller, K.-R. (1998). Efficient BackProp. Neural Networks: Tricks of the Trade. [doi:10.1007/978-3-642-35289-8_3]