s15 序列模型:RNN → LSTM → GRU
文本是有顺序的——"我爱你"和"你爱我"是两回事。序列模型专门处理这种时序数据。
一、为什么序列需要专门的模型?
传统的全连接网络(MLP)和卷积网络(CNN)在处理序列数据时有根本性的局限:
MLP 的问题:
- 输入维度固定——无法处理变长序列
- 每个输入位置独立处理——"我/爱/你"三个词分别进入三层神经元,没有时序关联
- 参数与位置绑定——第 1 个词的权重只能学第 1 个位置的特征
CNN 的问题:
- 卷积核有固定感受野——只能看到局部上下文
- 虽然可以通过堆叠层增大感受野,但长距离依赖仍然难以建模
- 不是为序列专门设计的,缺乏显式的时序记忆机制
序列模型的核心需求:
- 变长输入处理能力
- 参数跨时间步共享(同一套参数处理不同位置)
- 显式的记忆机制,能捕捉长距离依赖
- 输入顺序敏感
循环神经网络(RNN)通过一个优雅的循环结构同时满足了以上所有需求。
二、RNN:循环的魔力
2.1 核心公式
RNN 的核心是一个在时间上反复执行的"细胞":
:时间步 的隐藏状态(hidden state),是网络的"记忆" :上一个时间步的隐藏状态——携带了历史信息 :当前时间步的输入 :隐藏状态到隐藏状态的权重矩阵(循环连接) :输入到隐藏状态的权重矩阵 :激活函数,将状态压缩到 之间,防止数值爆炸
核心直觉:
的内容是 (当前输入)和 (历史记忆)的加权组合。这就像人在阅读时——每读一个词,大脑都会结合刚才记住的信息来理解当前内容。
2.2 时间展开(Unrolling)
同一个 RNN 细胞(同一套参数
x_1 → [RNN] → h_1 → [RNN] → h_2 → [RNN] → h_3 → ... → h_T
↑共享W_h,Wx↑ ↑共享W_h,Wx↑这种参数共享是 RNN 能处理变长序列的关键——不管序列多长,都用同一套参数,模型大小不随序列长度增长。
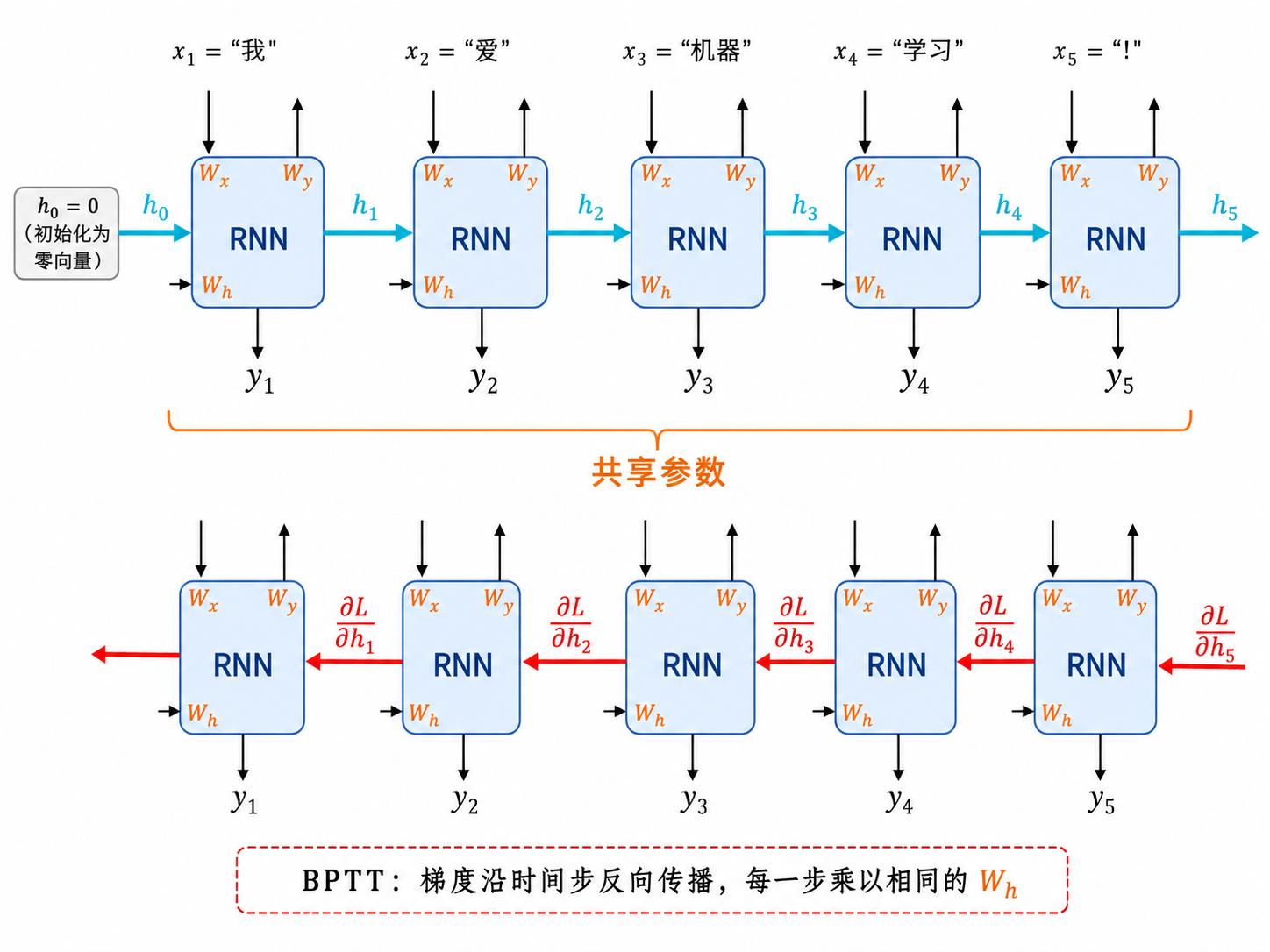
2.3 BPTT:沿时间反向传播
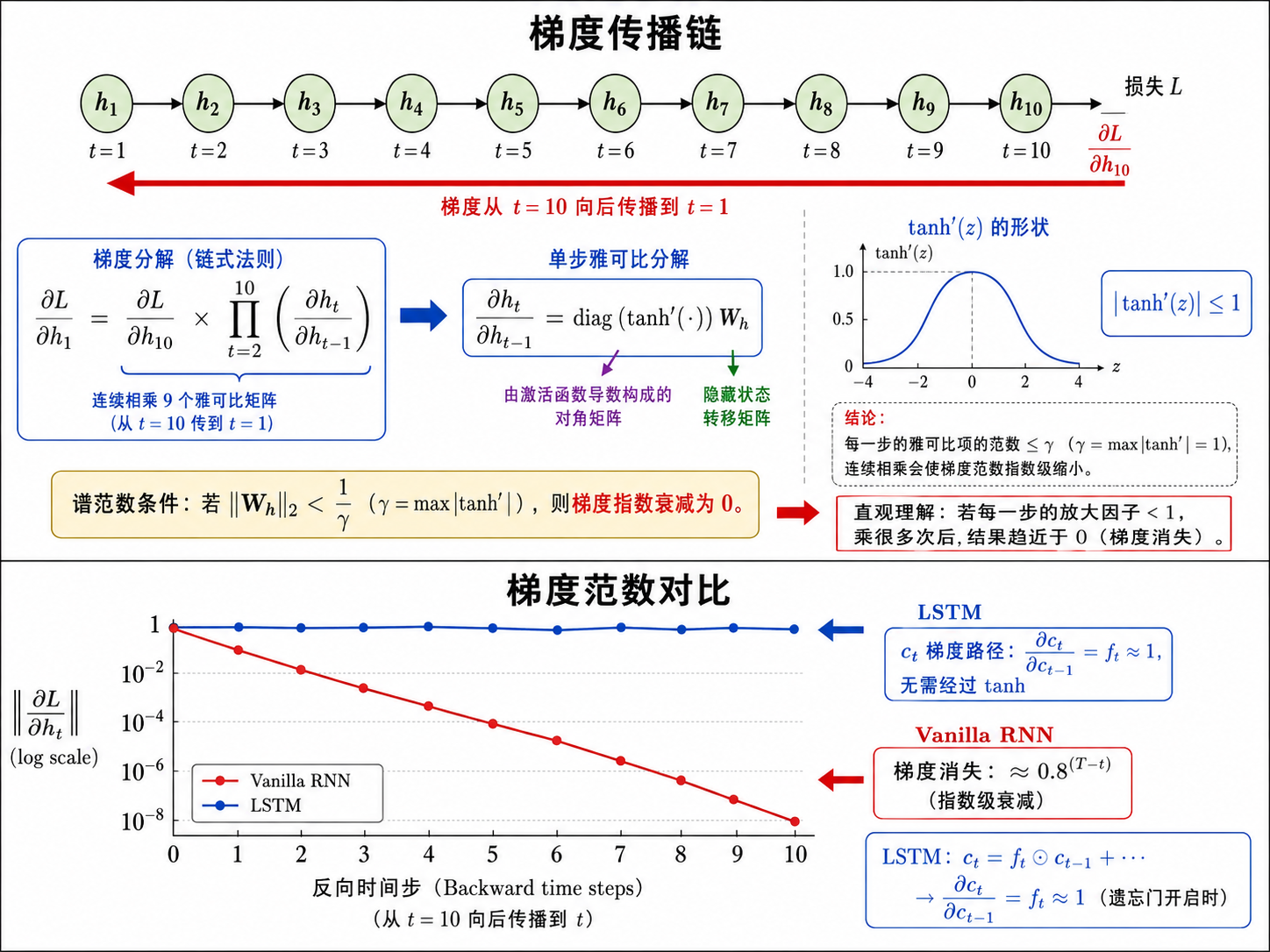
训练 RNN 时,梯度需要沿着时间步往回传播,这叫做通过时间的反向传播(Backpropagation Through Time, BPTT)。
损失
而
其中
三、LSTM:带三个门的记忆细胞
3.1 为什么需要门?
RNN 的梯度消失本质是因为信息以乘法的方式在时间中传播。每一步的隐藏状态既有用信息也有无用信息,而
LSTM(Long Short-Term Memory,长短期记忆网络,Hochreiter & Schmidhuber, 1997)引入了细胞状态(cell state)
3.2 细胞状态:一条信息高速公路
:遗忘门(forget gate),控制哪些旧信息需要丢弃 :输入门(input gate),控制哪些新信息需要写入 :候选细胞状态,由当前输入产生的新信息 :逐元素乘法
因为
这就是 LSTM 解决梯度消失的关键——给信息流动留了一条不必经过非线性激活的"高速公路"。
3.3 三个门的完整公式
遗忘门 — 决定丢弃细胞状态中的哪些信息:
输入门 — 决定把哪些新信息存入细胞状态:
候选细胞状态 — 由当前输入产生的新信息候选:
细胞状态更新 — 遗忘旧信息,加入新信息:
输出门 — 决定输出隐藏状态的哪些部分:
其中
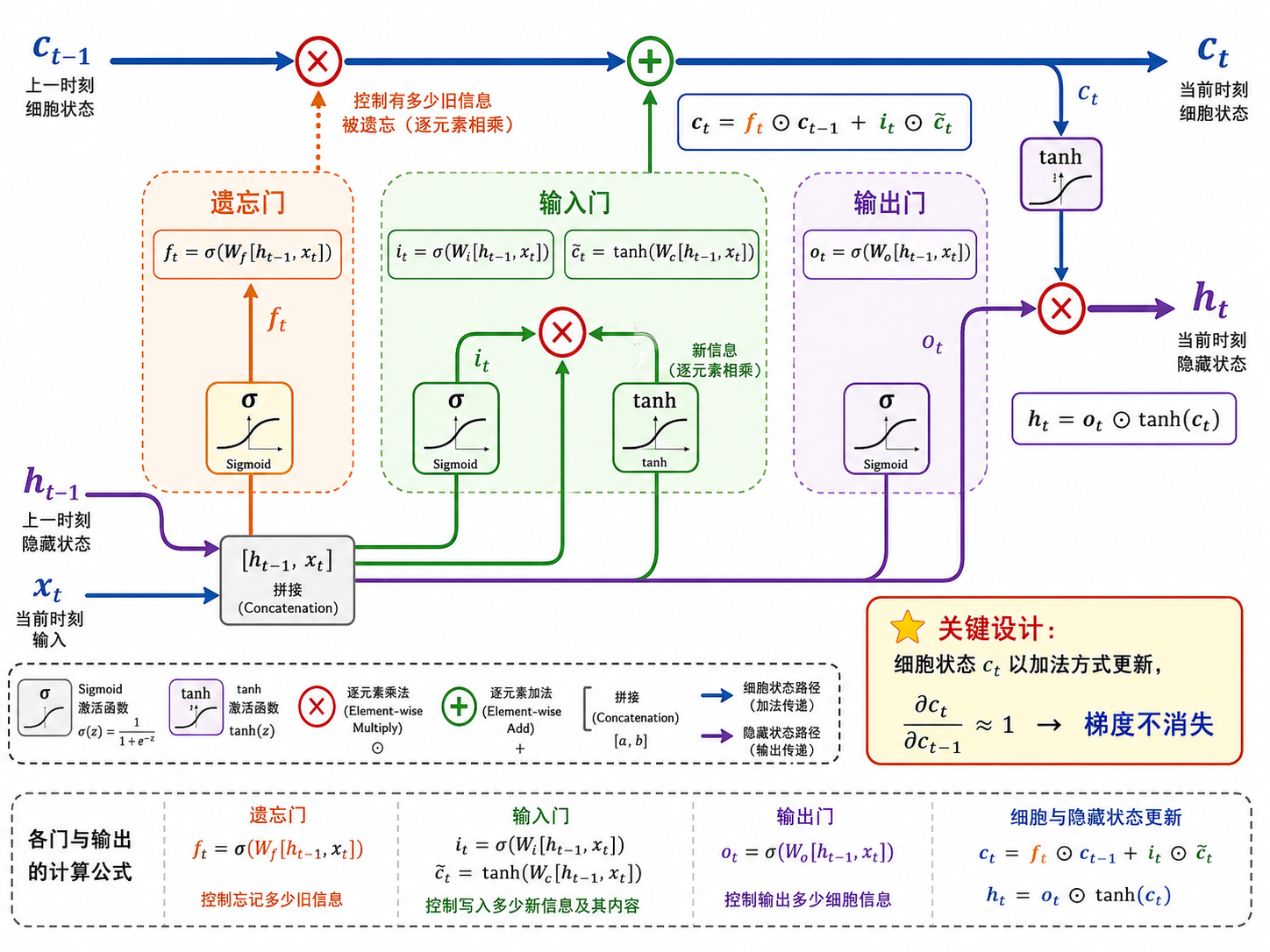
3.4 门的直觉
| 门 | 作用 | 直觉 |
|---|---|---|
| 遗忘门 | "读到句号,清空前文状态" | |
| 输入门 | "遇到主语,更新句法角色" | |
| 输出门 | 筛选哪些信息输出到 | "只输出当前需要的特征" |
LSTM 就像一个有条理的学生做笔记:遗忘门决定擦掉笔记中不再重要的部分,输入门决定写下新的知识点,输出门决定在回答问题时提取笔记的哪部分。
四、GRU:LSTM 的精简版
Cho et al. (2014) 提出 GRU(Gated Recurrent Unit),将 LSTM 的三个门精简为两个,并且去掉了独立的细胞状态:
重置门(reset gate)— 控制忽略多少历史信息:
更新门(update gate)— 控制保留多少旧状态 vs 写入多少新状态:
候选隐藏状态— 用重置门过滤后的历史 + 当前输入:
最终隐藏状态— 更新门做线性插值:
GRU 的核心直觉是
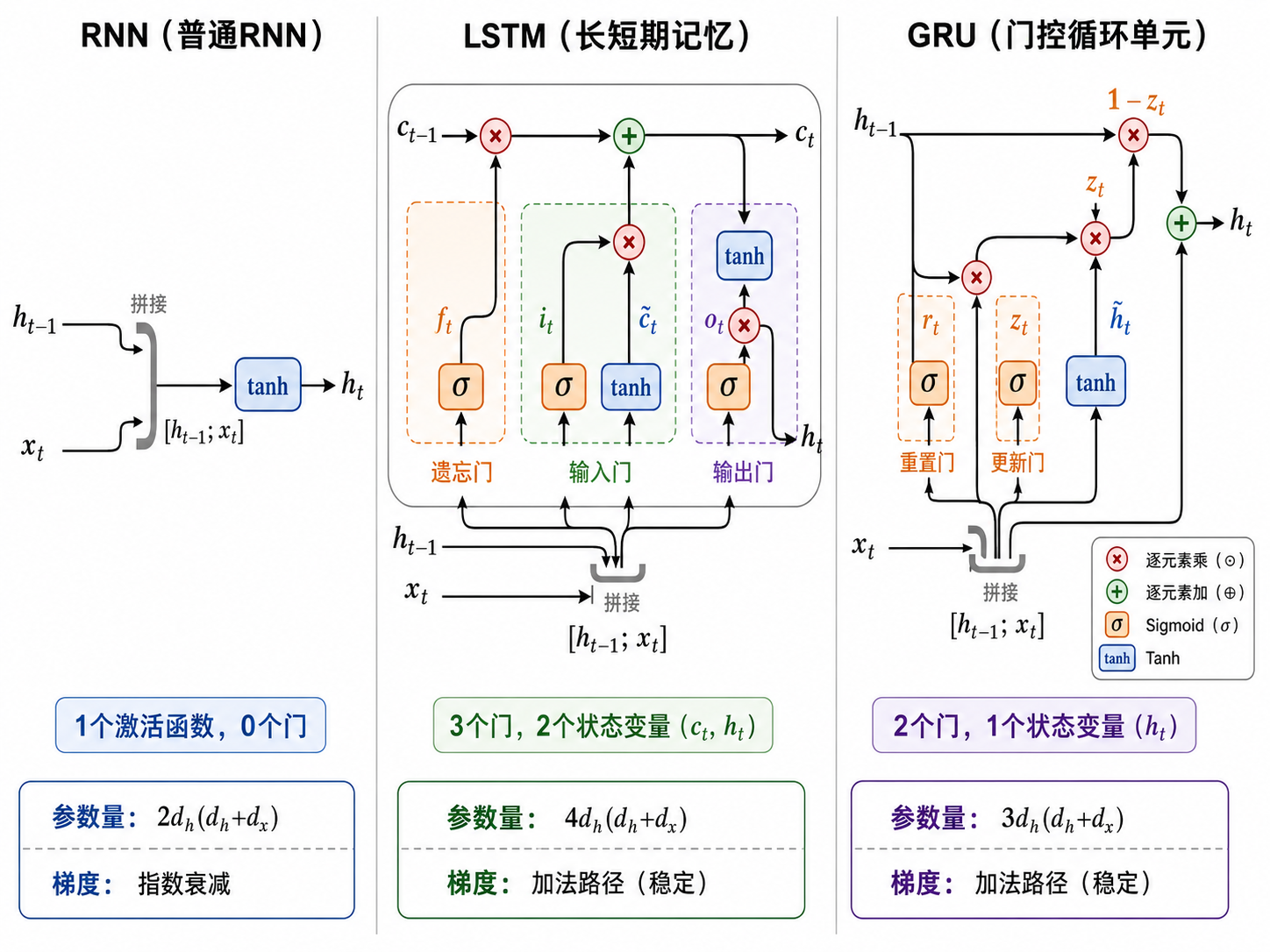
五、RNN vs LSTM vs GRU 对比
| 特性 | RNN | LSTM | GRU |
|---|---|---|---|
| 门数量 | 0 | 3 | 2 |
| 状态变量 | |||
| 梯度传播 | 指数衰减 | 加法路径(稳定) | 加法路径(稳定) |
| 参数量 | |||
| 训练速度 | 快 | 慢 | 中等 |
| 长序列表现 | 差 | 最好 | 好 |
| 典型场景 | 简单时序预测 | 机器翻译、复杂序列 | 当 LSTM 太大时替代 |
六、双向 RNN
标准 RNN/LSTM/GRU 只能从左到右处理序列——
双向 RNN(Bidirectional RNN)同时运行两个独立的循环网络:
- 前向 RNN:从左到右处理,
- 后向 RNN:从右到左处理,
- 拼接输出:
双向 RNN 在序列标注(NER、词性标注)和文本分类中极其有效。但无法用于自回归生成(因为你无法看到"未来"的词)。
七、RNN vs Transformer:时代的交替
2017 年 Transformer 出现后,RNN 系模型在 NLP 中的主导地位逐渐被取代。但这并不意味着 RNN 不再重要:
| 场景 | 选择 |
|---|---|
| 长序列(>2048 tokens)且追求最优效果 | Transformer(全局自注意力) |
| 流式/实时处理、逐时间步推理 | RNN/LSTM(自然支持) |
| 计算资源受限 | GRU(参数少、推理快) |
| 时间序列预测(金融、传感器) | LSTM(仍广泛使用) |
| 学习 RNN 原理、BPTT、门控机制 | 必须掌握(本章重点) |
学习价值:RNN→LSTM→GRU→Transformer 这条技术演进路线的每一步都解决了一个明确的问题。只有理解了每一步"为什么",才能真正理解 Transformer 的注意力机制"好在哪里"。
八、本节小结
| 概念 | 一句话总结 |
|---|---|
| RNN | 参数共享的循环结构,用 |
| BPTT | 梯度沿时间反向传播,连乘导致梯度消失 |
| LSTM 遗忘门 | sigmoid 输出 0~1,控制丢弃哪些旧信息 |
| LSTM 输入门 | sigmoid 输出 0~1,控制写入哪些新信息 |
| LSTM 输出门 | sigmoid 输出 0~1,控制暴露哪些信息 |
| 细胞状态 | 加法更新的信息高速路, |
| GRU | LSTM 精简版:合并 |
| 双向 RNN | 前向+后向处理,适合标注任务 |
| Transformer | s16 主题,注意力取代循环连接 |
下一节 s16 Attention 与 Transformer 将讨论:序列模型的 seq2seq 架构遇到什么瓶颈,注意力机制如何优雅地解决它,并最终催生了取代 RNN 的全新范式。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Hochreiter, S. & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation. (LSTM) [doi:10.1162/neco.1997.9.8.1735]
- Cho, K., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP 2014. (GRU) [arXiv:1406.1078]
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. NeurIPS 2014. (Seq2Seq) [arXiv:1409.3215]