s05 计算图与前向传播
从一个神经元开始,理解神经网络如何从输入走到输出 —— 感知机、计算图、激活函数与完整的前向传播流程
一、感知机:神经网络的最小单元
1958 年,Frank Rosenblatt 发明了感知机(Perceptron)——第一个可学习的人工神经元模型。它是所有现代神经网络的鼻祖,理解它就是理解深度学习的"原子"。
1.1 数学模型
一个感知机做的事情非常简单:接收多个输入信号,加权求和,经过一个激活函数,输出结果。
逐项拆解:
:输入特征(例如:花瓣长度、花瓣宽度、花萼长度……) :权重(weights)——每个输入特征的重要性。 越大,说明第 个特征对最终决策的影响越大 :偏置(bias)——相当于一个"门槛",控制神经元被激活的容易程度 :净输入(net input),通常记为 :激活函数(activation function)——将 映射为最终输出
Rosenblatt 的原始感知机使用**阶跃函数(Step Function)**作为激活函数:
直觉类比:感知机就像一个"投票加权的决策者"。每个输入
投一票,权重 代表这一票的分量。所有票加权求和后,如果总分超过门槛 (即 ),就输出 1(同意);否则输出 0(否决)。
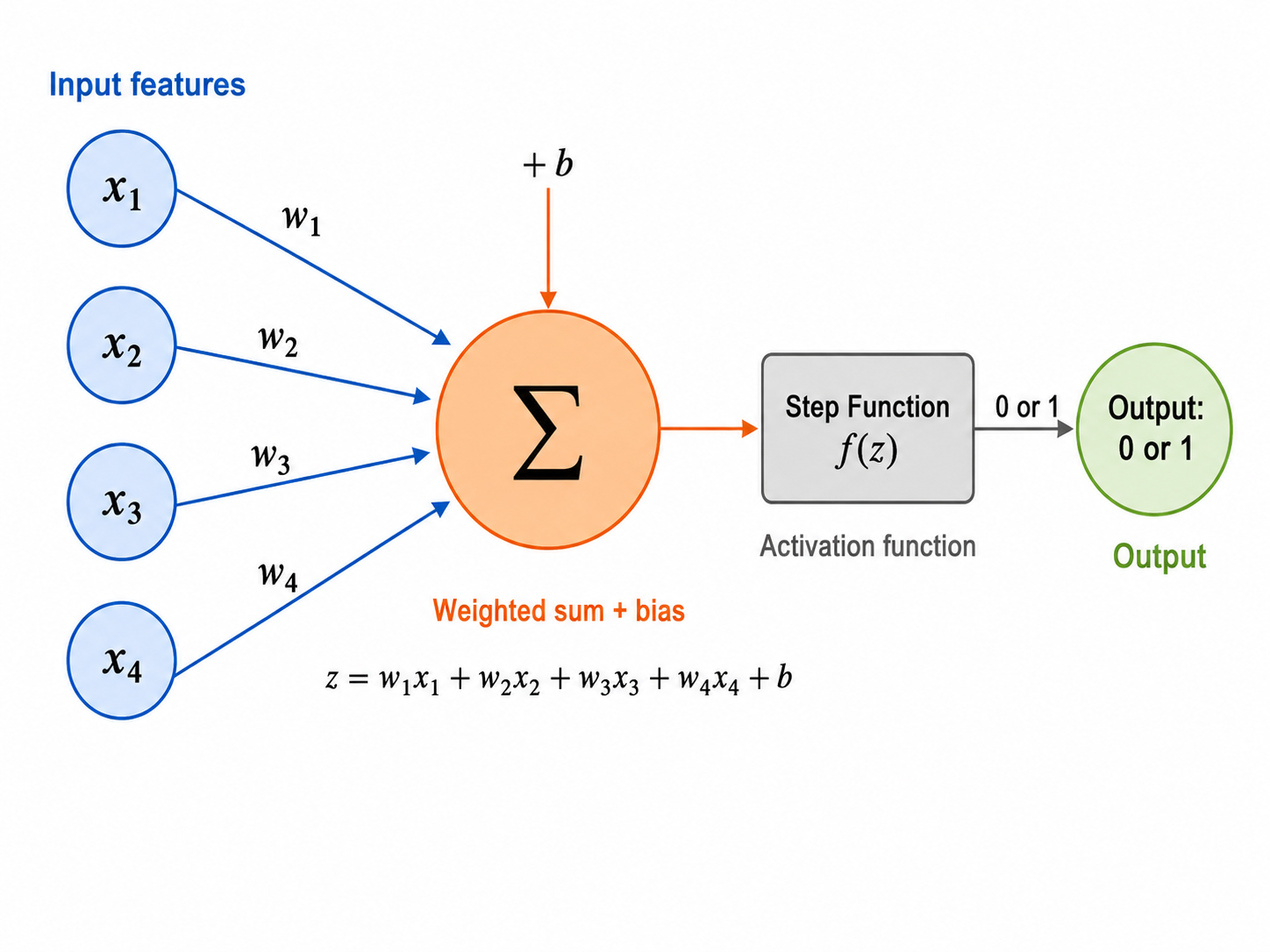
生图提示词(图 05-05):A clean educational diagram of a single perceptron (artificial neuron). Left side: 4 input nodes labeled x₁, x₂, x₃, x₄ in blue circles. Each has an arrow pointing to a central circular node. The arrows are labeled with weights w₁, w₂, w₃, w₄. The central node shows "Σ" (summation symbol) with a separate small "+ b" (bias) input entering from the top. Below the summation, show the formula "z = w₁x₁ + w₂x₂ + w₃x₃ + w₄x₄ + b". An arrow leads from the summation node to a small rectangular block labeled "Step Function f(z)". The block outputs either 0 or 1. Right side: a single output node in green labeled "Output: 0 or 1". The entire diagram should have clear color-coded sections: input features (blue), weighted sum + bias (orange), activation function (gray), output (green). Use a clean flat design style suitable for a textbook. White background, no grid, no title text on the image itself. English labels only. Professional, minimal, easy to understand at a glance.
1.2 几何直觉:一条直线划分空间
感知机有一个非常直观的几何解释。方程
- 直线上方的点:
,感知机输出 1(正类) - 直线下方的点:
,感知机输出 0(负类)
权重向量
对于更高维的特征空间,这条"直线"推广为超平面(Hyperplane)——原理完全相同。
1.3 感知机的致命局限:XOR 问题
1969 年,Minsky 和 Papert 在《感知机》一书中证明了一个致命结论:单层感知机无法解决 XOR(异或)问题。
XOR 的真值表:
| XOR 输出 | ||
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
在二维平面上标出这四个点,你会发现:没有任何一条直线能将输出为 1 的点((0,1) 和 (1,0))与输出为 0 的点((0,0) 和 (1,1))分开。XOR 是线性不可分的。
这个证明直接导致了 1970 年代 AI 的第一次寒冬——如果最简单的 XOR 都解决不了,神经网络还有什么前途?
出路在哪? 把多个感知机堆叠起来,构成多层网络。中间层(隐藏层)可以将原始输入空间映射到一个新的特征空间,在新的空间中,XOR 变得线性可分。
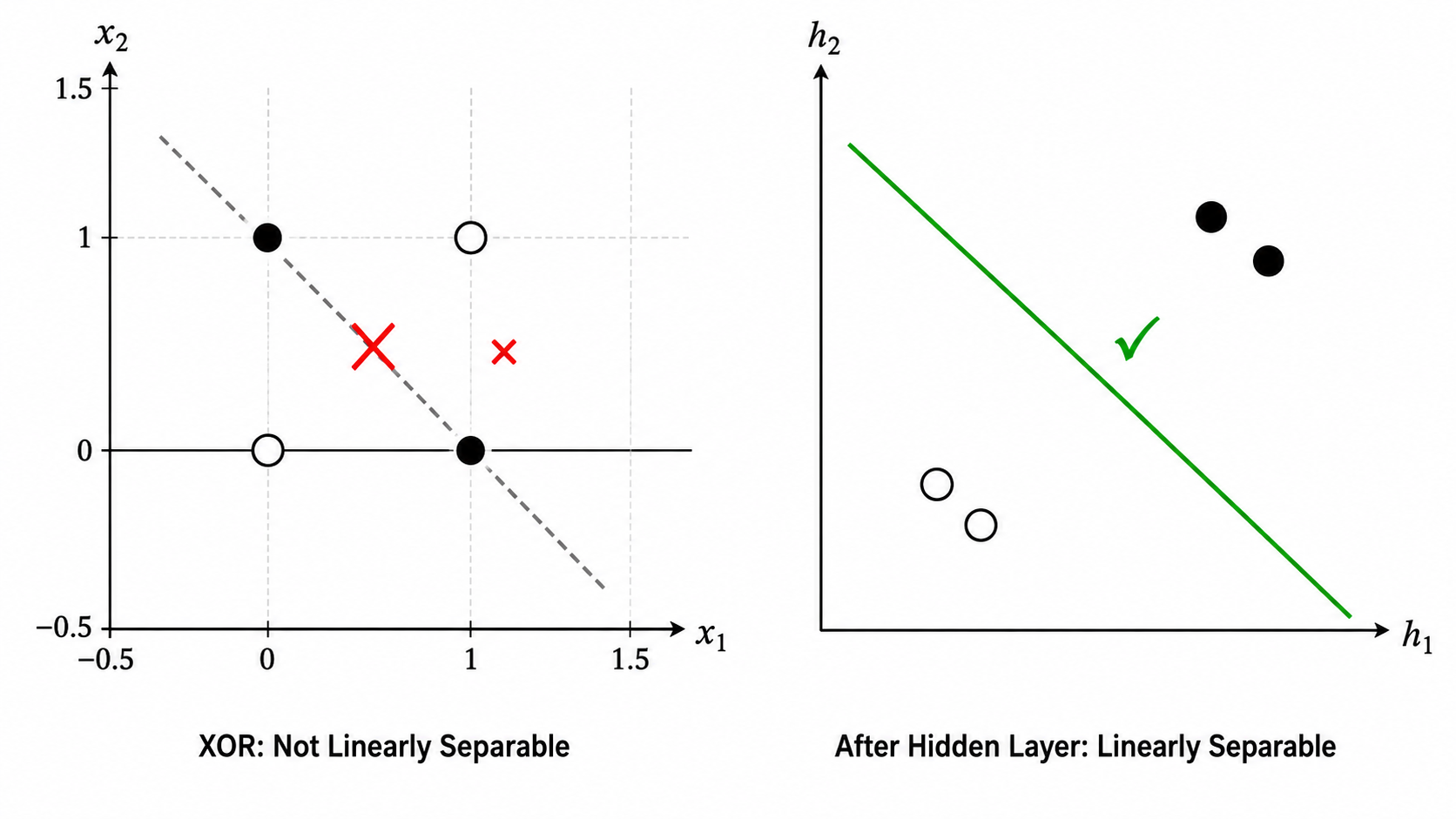
生图提示词(图 05-06):A two-panel educational diagram explaining the XOR problem. LEFT PANEL: A clean 2D coordinate grid (x₁ horizontal, x₂ vertical, range -0.5 to 1.5). Four data points: (0,0) as hollow circle, (1,1) as hollow circle, (0,1) as solid filled circle, (1,0) as solid filled circle. A dashed diagonal line is drawn attempting to separate them. A red X or strike-through symbol over the line indicates failure. Label bottom: "XOR: Not Linearly Separable". RIGHT PANEL: Same four points but now in a transformed space (axes labeled h₁ and h₂ instead of x₁ and x₂). The hollow points are clustered together (bottom-left), solid points clustered together (top-right). A clean separating line divides them successfully with a green checkmark. Label bottom: "After Hidden Layer: Linearly Separable". The dividing line from the left panel can be gray and marked with ✗, while the right panel's line should be green with ✓. Clean flat design, white background, no grid on the transformed space, English labels only.
二、从感知机到多层网络
2.1 为什么堆叠能解决问题?
一个感知机 = 一个线性分类器 = 一条直线。它能解决的问题是有限的。
多层感知机(MLP) 的解决方案是:用第一层(隐藏层)的多个感知机分别学习不同的线性分界,然后将它们的输出作为第二层的输入。第二层在这些"中间特征"的基础上再做一次线性分类——这个"线性"是在隐藏层学到的新特征空间中的线性,而这个新空间已经是原始输入空间的非线性变换。
类比:一个感知机就像是只能看到 2D 投影的人——在他眼里 XOR 不可分。两个堆叠的感知机就像是先由两个人分别从不同角度观察数据(每人画一条线),第三个人综合前两人的判断结果来做最终决策(再画一条线)——三人协作,XOR 迎刃而解。
2.2 数学形式:从一层到多层
一个有
其中
每一层
这里
核心直觉:神经网络就是把简单函数(线性变换 + 非线性激活)一层层嵌套起来。通过足够多的层和神经元,理论上可以逼近任意复杂的函数——这就是万能逼近定理(Universal Approximation Theorem)。
三、什么是计算图?
计算图(Computational Graph)是一种有向无环图(DAG),用于描述数学计算的结构:
- 节点(Node):代表一个操作(operation),比如加法、乘法、矩阵乘法、激活函数等。
- 边(Edge):代表数据(张量)在操作之间的流动方向。
计算图的核心思想是分解:把复杂的函数拆成一系列基本操作,每个操作只做一件简单的事。比如
x ──→ [MatMul: W·x] ──→ [Add: +b] ──→ [ReLU] ──→ a为什么计算图如此重要?三个原因:
- 前向传播清晰可追踪:输入数据沿着图的边一步步流动,最终得到输出。
- 反向传播变得简单:从输出端往回走,每个节点只需要知道自己的"局部导数规则",就能把梯度传回去。这叫做自动微分(Automatic Differentiation)。
- 框架实现的基础:PyTorch、TensorFlow、JAX 的底层都是动态或静态地构建计算图,然后自动求导。
可以把计算图想象成工厂的流水线:每个工人(节点)只负责一道工序,原材料(数据)在传送带(边)上流动,最终组装成产品(输出)。
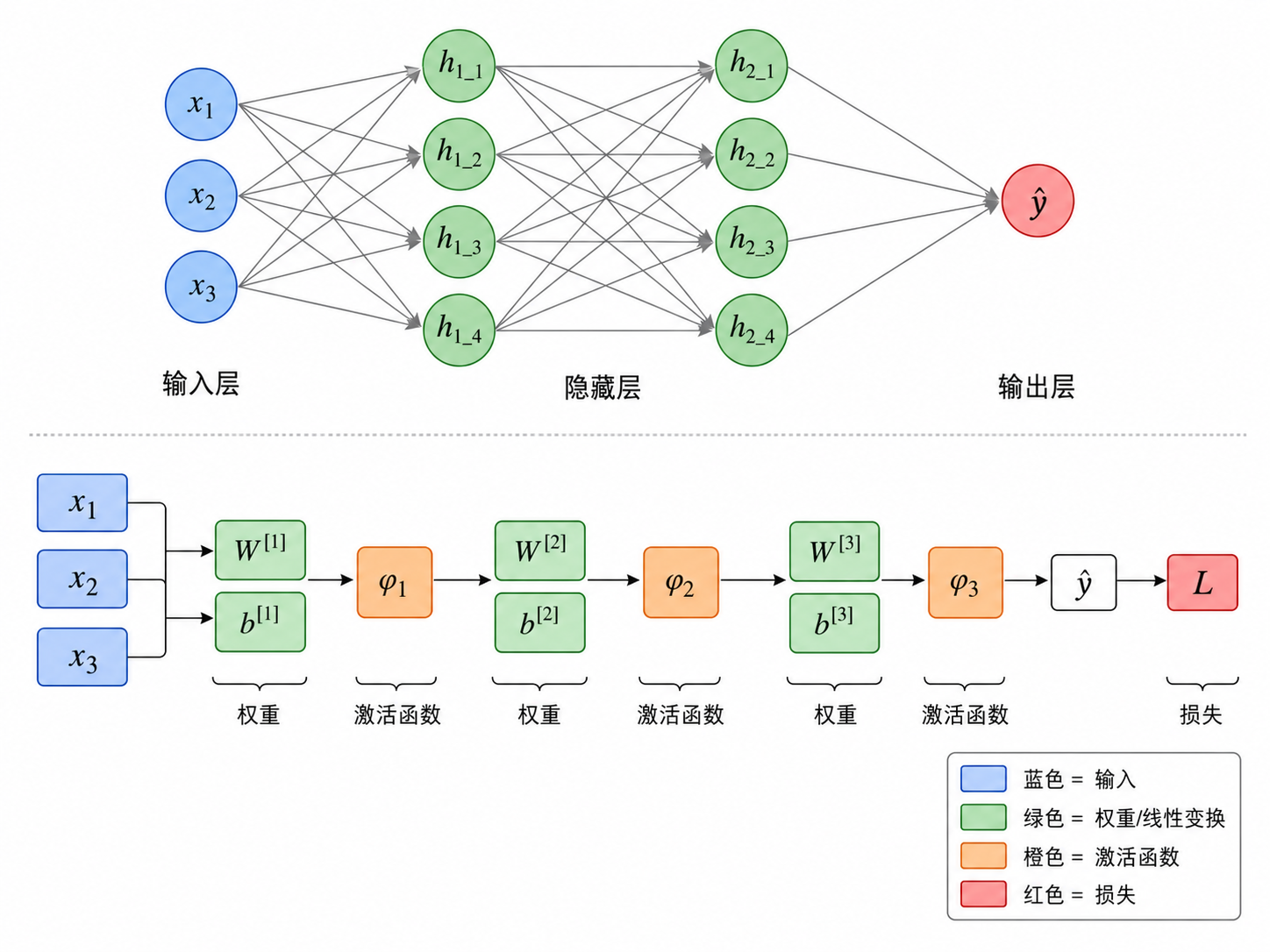
四、前向传播的完整流程
让我们跟踪一个输入样本
第 0 步:输入
其中
第
子步骤 1:线性变换
的形状为 (输出维度 × 输入维度) 的形状为 的形状为 (该层的"预激活"值)
子步骤 2:非线性激活
是逐元素(element-wise)的非线性函数 是该层的最终输出,也是下一层的输入
第 L+1 步:损失计算
最后一层的输出
其中
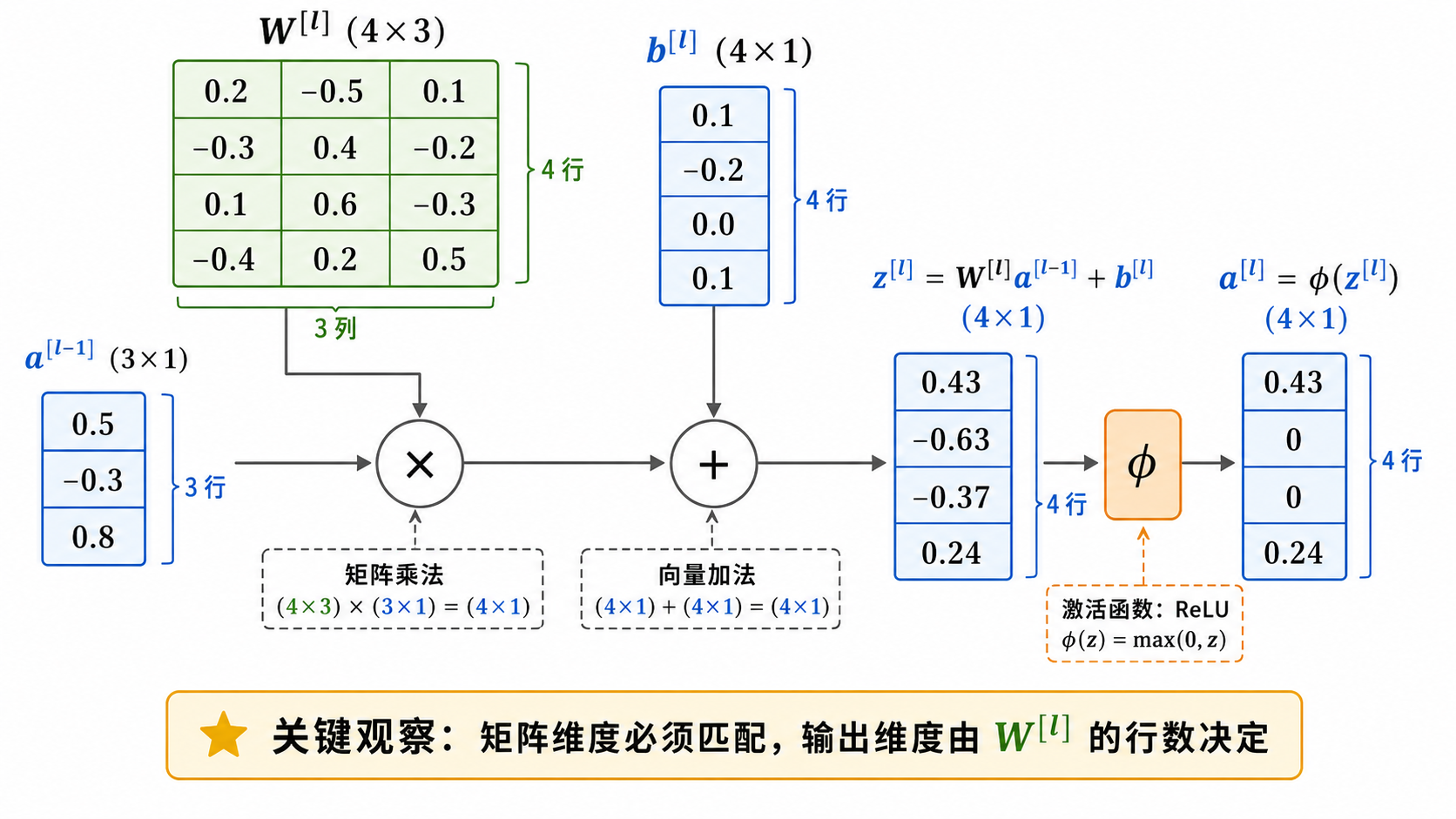
五、激活函数深度解析
激活函数是神经网络非线性能力的来源。理解它们的特性和演进逻辑,是理解深度学习为什么有效的关键。
5.1 为什么必须是非线性的?
假设我们去掉激活函数(或使用恒等函数
两层线性变换的复合 = 一层线性变换。 再加多少层都没用——网络永远等价于一个单层线性模型,表达能力不会提升。
激活函数在每个线性变换之后引入了非线性扭曲,破坏了这种"可合并性"。这就是为什么没有激活函数的深度网络和浅层网络没有本质区别。
一句话:线性变换负责"投影"(改变视角),激活函数负责"弯曲"(创造非线性)。投影 + 弯曲,层层叠加,才能拟合任意复杂的函数。
5.2 五种主流激活函数
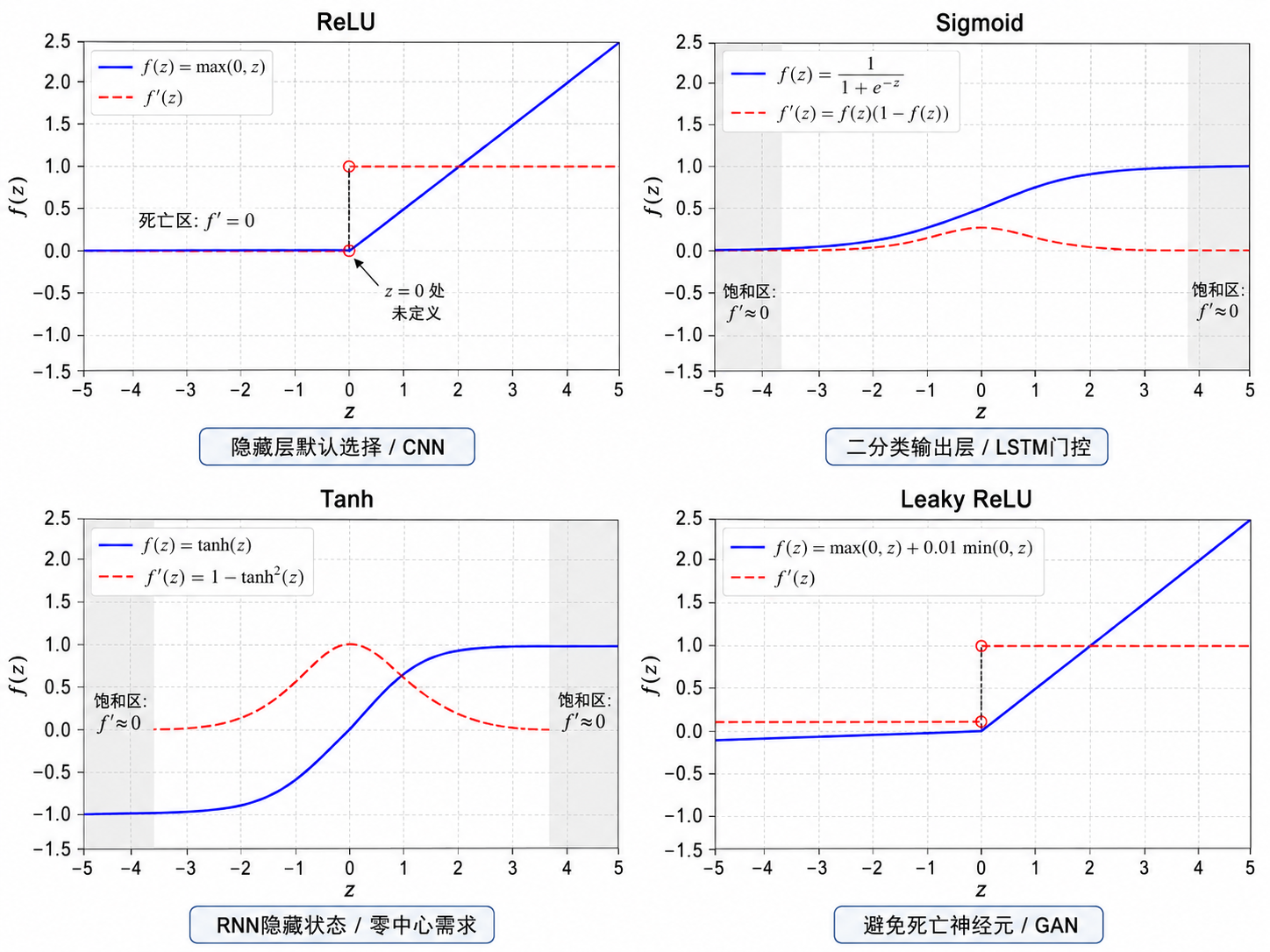
Sigmoid
- 输出范围:
,天然适合做概率解释 - 导数特性:最大值为
(在 处),两侧迅速衰减到接近 - 致命问题:当
时,导数 ,梯度无法传回浅层——梯度消失的元凶 - 当前用途:仅用于二分类输出层(配合 BCE 损失)或 LSTM 遗忘门
Tanh
- 输出范围:
,零中心 → 比 sigmoid 更适合隐藏层 - 导数特性:最大值为
(在 处),比 sigmoid 的 大 4 倍,但仍会在 时饱和 - 当前用途:RNN/LSTM 的隐藏状态(零中心有助于序列建模)
ReLU(Rectified Linear Unit)
- 输出范围:
- 导数特性:正区间恒为
——彻底解决了正区间的梯度消失问题 - 核心优势:计算极简(只需一次
max操作),导数恒为 1 使得深层网络的梯度可以无损传播 - 死亡 ReLU 问题:一旦某个神经元对所有输入都输出
,梯度永远为 0,该神经元"死亡"且不可恢复 - 当前用途:CNN 和大多数 MLP 隐藏层的默认选择(2012-2018 年间的主导)
Leaky ReLU
- 改进点:负区间给一个很小的斜率(
),使得梯度在负区间也能微弱传播 - 解决什么:ReLU 的"死亡神经元"——即使
,梯度也不为 0 - 当前用途:对梯度敏感的架构(如 GAN),或当观察到明显的死亡 ReLU 问题时
GELU(Gaussian Error Linear Unit)
其中
- 核心思想:不是"一刀切"地决定 pass/discard,而是根据
的大小概率性地让信息通过。 越大,通过的概率越接近 1; 接近 0 时,"是否通过"是不确定的 - 为什么有效:引入了类似 Dropout 的随机正则化效果,但这是确定性的(由
计算,无需采样) - 当前用途:Transformer 架构的标准激活函数(BERT、GPT、ViT 等全部使用 GELU)
5.3 梯度特性对比:为什么 ReLU 赢了 Sigmoid?
理解激活函数的关键不在于它们的形状,而在于它们的导数值域。对于深度网络(10+ 层),反向传播的梯度需要连乘 10 个导数因子:
| 激活函数 | 导数最大值 | 导数最小值 | 远端饱和 | 深层梯度 |
|---|---|---|---|---|
| Sigmoid | 0.25 | ~0 | 指数衰减 | |
| Tanh | 1.0 | ~0 | 指数衰减 | |
| ReLU | 1 | 0 (负区间) | 正区间不饱和 | 正区间无损 |
| Leaky ReLU | 1 | 0.01 (负区间) | 正区间不饱和 | 正区间无损,负区间微弱 |
| GELU | ~1 | ~0 | 两端渐近 | 类似 ReLU 但更平滑 |
Sigmoid 的灾难:假设网络有 20 层,每层都用 sigmoid。在最好的情况下(每层
ReLU 的胜利:正区间的导数为 1,20 层连乘后…仍然是 1。这就是为什么 AlexNet(2012)用 ReLU 替代 sigmoid 后,训练速度快了 6 倍。
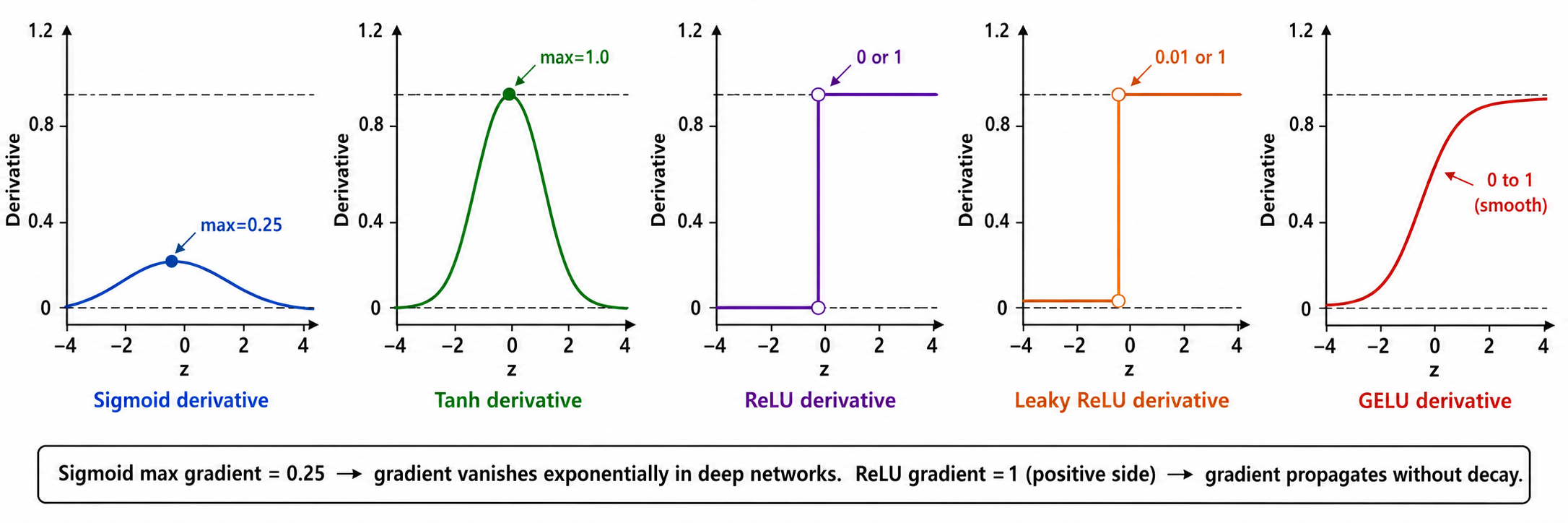
生图提示词(图 05-07):A clean educational figure showing the derivatives of 5 activation functions side by side in a row. Five small panels, each showing one derivative curve: (1) Sigmoid derivative - bell-shaped curve peaking at 0.25 at z=0, approaching 0 at z=±5, label "max=0.25". (2) Tanh derivative - bell-shaped curve peaking at 1.0 at z=0, approaching 0 at z=±3, label "max=1.0". (3) ReLU derivative - step function: 0 for z<0, 1 for z>0, label "0 or 1". (4) Leaky ReLU derivative - step function: 0.01 for z<0, 1 for z>0, label "0.01 or 1". (5) GELU derivative - smooth S-shaped curve approaching 0 for z<<0 and 1 for z>>0, label "0 to 1 (smooth)". Each panel has z on x-axis (range -4 to 4), derivative value on y-axis (range 0 to 1.2). Dashed horizontal reference lines at y=0 and y=1 in each panel. A bottom text annotation reads: "Sigmoid max gradient = 0.25 → gradient vanishes exponentially in deep networks. ReLU gradient = 1 (positive side) → gradient propagates without decay." Clean white background, flat design, English labels only. No title on the image.
5.4 演进逻辑
激活函数的演进不是随机的,每一步都为了解决前一步的明确问题:
Sigmoid → Tanh → ReLU → Leaky ReLU → GELU
│ │ │ │ │
│ │ │ │ └─ 随机正则化 + 平滑性 (Transformer)
│ │ │ └─ 解决死亡神经元 (GAN)
│ │ └─ 解决梯度消失 (CNN/MLP)
│ └─ 解决非零中心 (RNN)
└─ 最早使用,但存在梯度消失 + 非零中心两大缺陷选择建议:CNN/MLP 隐藏层用 ReLU(先试);Transformer 用 GELU(标配);二分类输出层用 Sigmoid;多分类输出层用 Softmax;发现死亡 ReLU 现象时换 Leaky ReLU。
六、为什么必须存储中间值?
在前向传播过程中,我们需要把每一层的中间结果存储下来——
具体来说,反向传播需要用到:
| 存储的值 | 用途 |
|---|---|
| 计算激活函数的导数 | |
| 计算权重梯度 | |
| 递推计算 |
这就是为什么训练神经网络需要比推理时更多的显存——前向传播的中间结果必须保留到反向传播完成。
这叫做计算换内存还是内存换计算的经典权衡。如果你不想存中间值,可以在反向传播时重新计算(Re-materialization / Checkpointing),这样可以节省显存但增加计算量——大模型训练常用的技巧。
七、训练目标与参数更新
学习的数学定义
前面说过,神经网络就是一个带参数的函数
其中
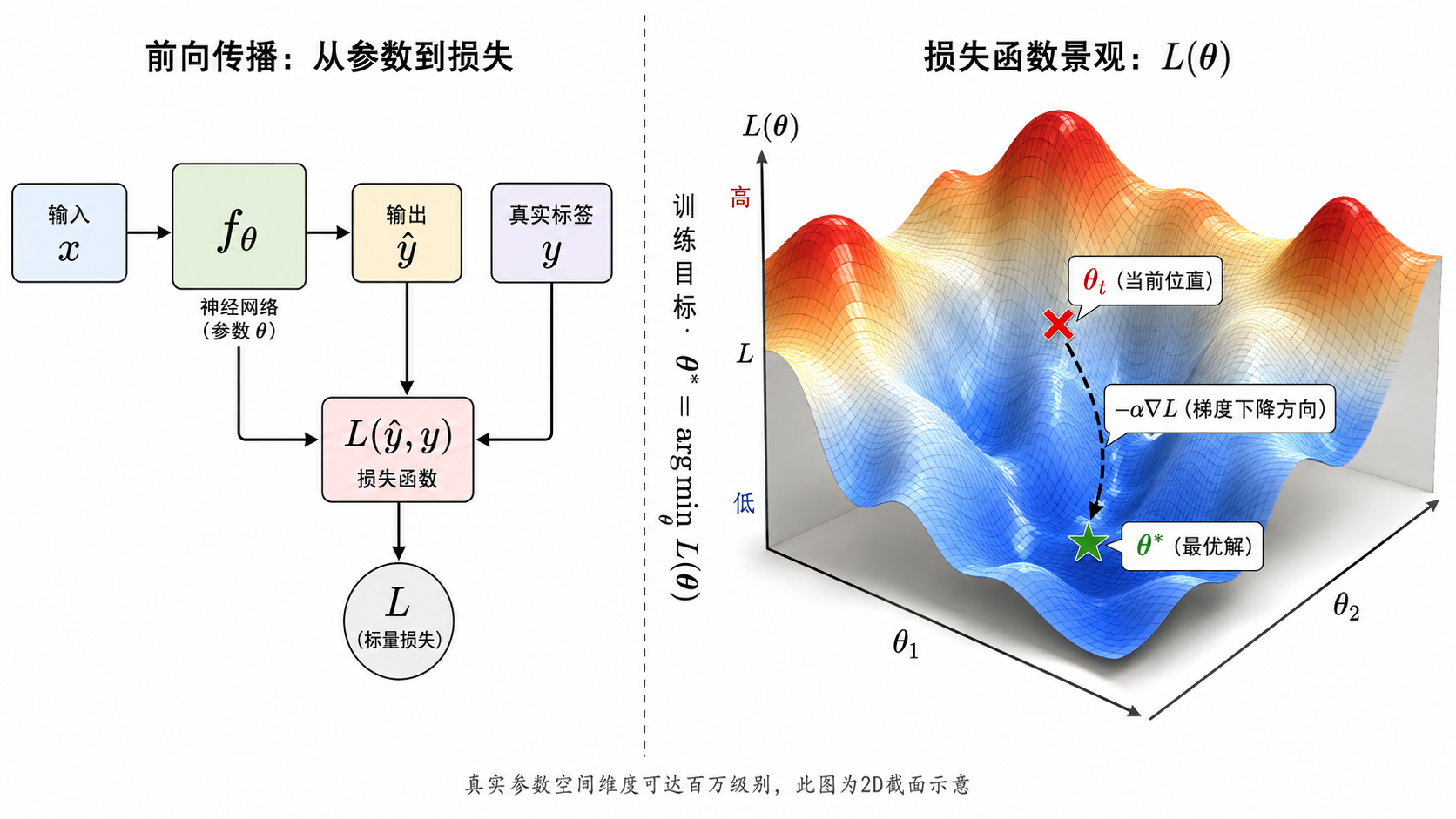
梯度下降的基本思想
我们无法直接解出
拆解这行公式:
:损失函数在当前位置 的梯度。梯度是一个向量,指向函数值上升最快的方向。 :学习率(Learning Rate),控制每一步走多远。 - 前面有个负号:因为我们想下降(找最小值),所以沿梯度的反方向走。
高维地形中的"下山"
如果把
- 他只能感知脚底的地面坡度(局部梯度)。
- 他不知道山的全局形状(非凸函数)。
- 他每一步沿最陡的下坡方向走一小段(梯度下降)。
- 学习率
就是他的步长——步长太大可能摔下悬崖(发散),步长太小下山太慢。
虽然真实神经网络的损失面是极度非凸的高维流形,但实践中梯度下降及其变体通常能找到很好的局部最优解(甚至全局最优)。这是深度学习"反直觉地有效"的核心秘密之一。
关键认识:反向传播的职责是回答"每个参数对当前损失有多少责任"(即高效计算
)。而优化器(SGD、Adam 等)的职责是回答"知道责任之后,这一步该怎么改参数"。这两件事分工明确,但都依赖于对计算图的理解。
八、前向传播的代码实现要点
在 code/demo.py 中,我们用纯 NumPy 实现了一个 3 层 MLP 的前向传播。关键实现细节:
1. 参数初始化
权重不能初始化为全 0——那样所有神经元会学到相同的特征。通常使用:
- He 初始化(配合 ReLU):
- Xavier 初始化(配合 tanh/sigmoid):
2. 中间值存储
前向传播时,每一层的
3. Batch 处理
实际训练时,数据以 mini-batch 形式传入。此时前面的公式需要微调:输入
九、本节小结
| 概念 | 一句话 |
|---|---|
| 感知机 | 加权求和 + 激活函数,神经网络的"原子" |
| XOR 问题 | 单层感知机的致命局限——线性不可分 |
| 多层网络 | 多个感知机堆叠,隐藏层做非线性特征变换 |
| 计算图 | 用节点和边描述数学运算的有向无环图 |
| 前向传播 | 数据沿着计算图从输入流向输出 |
| 激活函数 | 引入非线性,破坏线性变换的可合并性 |
| 梯度消失 | sigmoid 导数 ≤0.25,深层连乘后梯度指数衰减 |
| ReLU 的胜利 | 正区间导数恒为 1,梯度可以无损传播到浅层 |
| GELU | Transformer 标配:概率性通过 + 平滑性 |
| 中间值存储 | 为反向传播保留 |
| 训练目标 |
下一节 s06 反向传播与链式法则 将详细拆解:梯度如何从损失出发,沿着计算图一层层传回到每一个参数。前向传播存储的中间值,将在那里被一一"消费"。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review.
- Minsky, M. & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
- He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. ICCV 2015. (He 初始化) [arXiv:1502.01852]
- Glorot, X. & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. AISTATS 2010. (Xavier 初始化) [PMLR]
- Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks. (Universal Approximation Theorem) [doi:10.1016/0893-6080(89)90020-8]