s13 图像生成:GAN、VAE 与扩散模型
让神经网络"创造"图像 —— 三种生成范式的原理与对比
一、生成模型的目标
图像生成的核心是学习数据分布
一旦学好了
三种主流方法以完全不同的方式逼近
| 方法 | 建模方式 | 采样方式 |
|---|---|---|
| GAN | 隐式(不需要显式 | 从噪声 |
| VAE | 显式(优化 ELBO) | 从学到的潜变量后验中采样 |
| Diffusion | 显式(最小化去噪误差) | 从纯噪声逐步去噪恢复图像 |
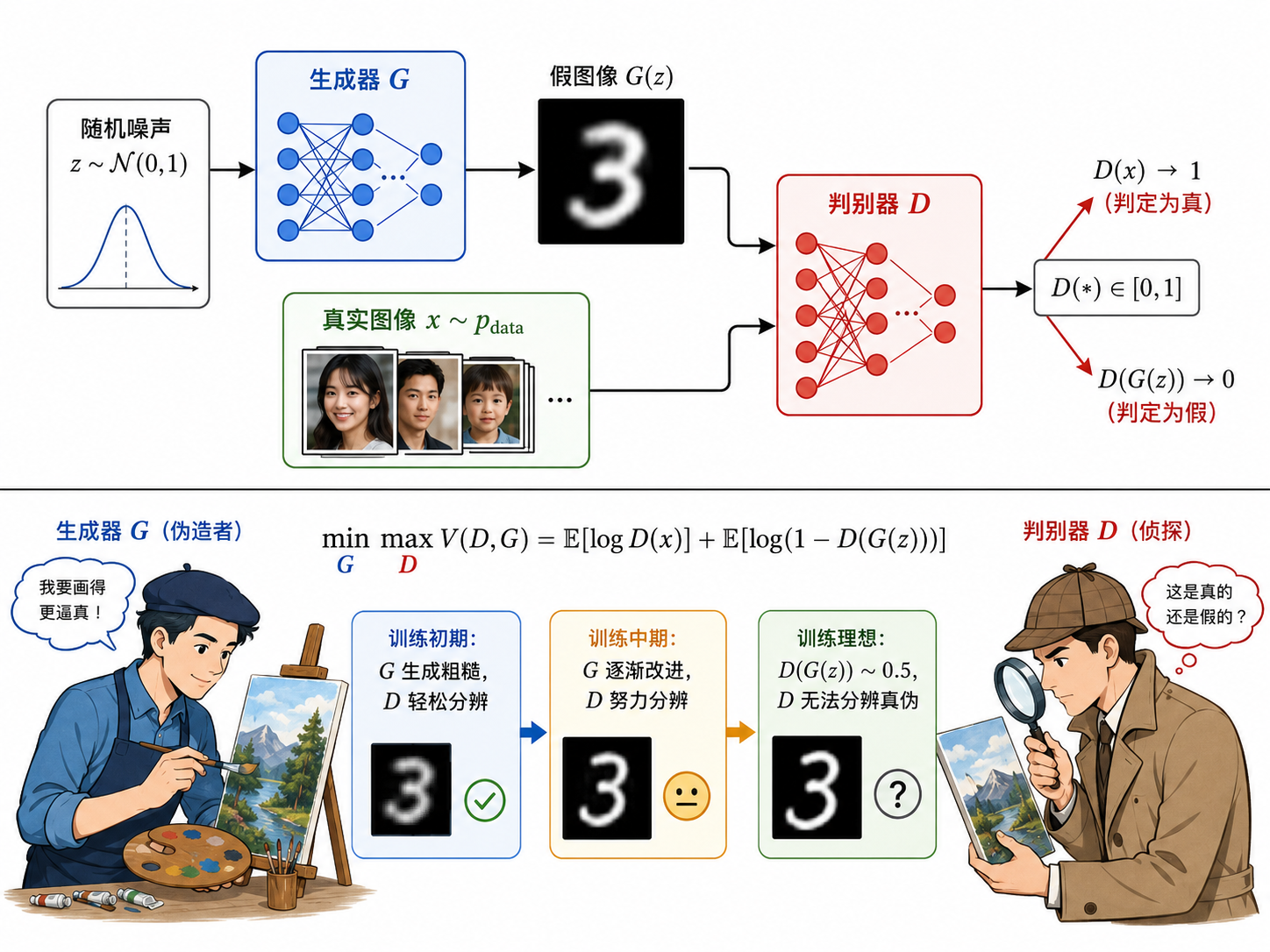
二、GAN:生成对抗网络 (2014)
2.1 核心思想:博弈论
GAN 由两个网络组成,它们相互对抗、共同进化:
- 生成器
:接收随机噪声 (通常是高斯分布),输出一张假图像 。目标是"骗过"判别器。 - 判别器
:接收一张图像(可能是真的也可能是假的),输出一个概率 表示图像为真的概率。目标是正确区分真假。
2.2 数学形式:Minimax Game
GAN 的训练是一个极小极大博弈:
拆解这行公式:
:判别器看到真实图像时,希望输出接近 1(真实),即 尽可能大。 :判别器看到假图像 时,希望输出接近 0(虚假),即 尽可能大。 - 生成器的目标相反:希望
接近 1,即 尽可能小。
2.3 训练过程
GAN 采用交替训练策略:
- 训练判别器:固定
,优化 以更好地区分真假 - 训练生成器:固定
,优化 以生成更逼真的图像 - 交替重复,直到
生成的图像足以以假乱真
理论上,当
2.4 GAN 的训练困难
GAN 训练出了名的不稳定,主要问题包括:
- 模式坍塌(Mode Collapse):生成器学会了"作弊"——不管输入什么
,都输出相同的少数几张看起来逼真的图像。生成的分布只覆盖了真实分布的少数几个模式。 - 梯度消失:当判别器太强时,
, ,生成器的梯度几乎为 0,无法学习。 - 训练振荡:
和 的博弈可能不会收敛,而是在不同策略间来回振荡。
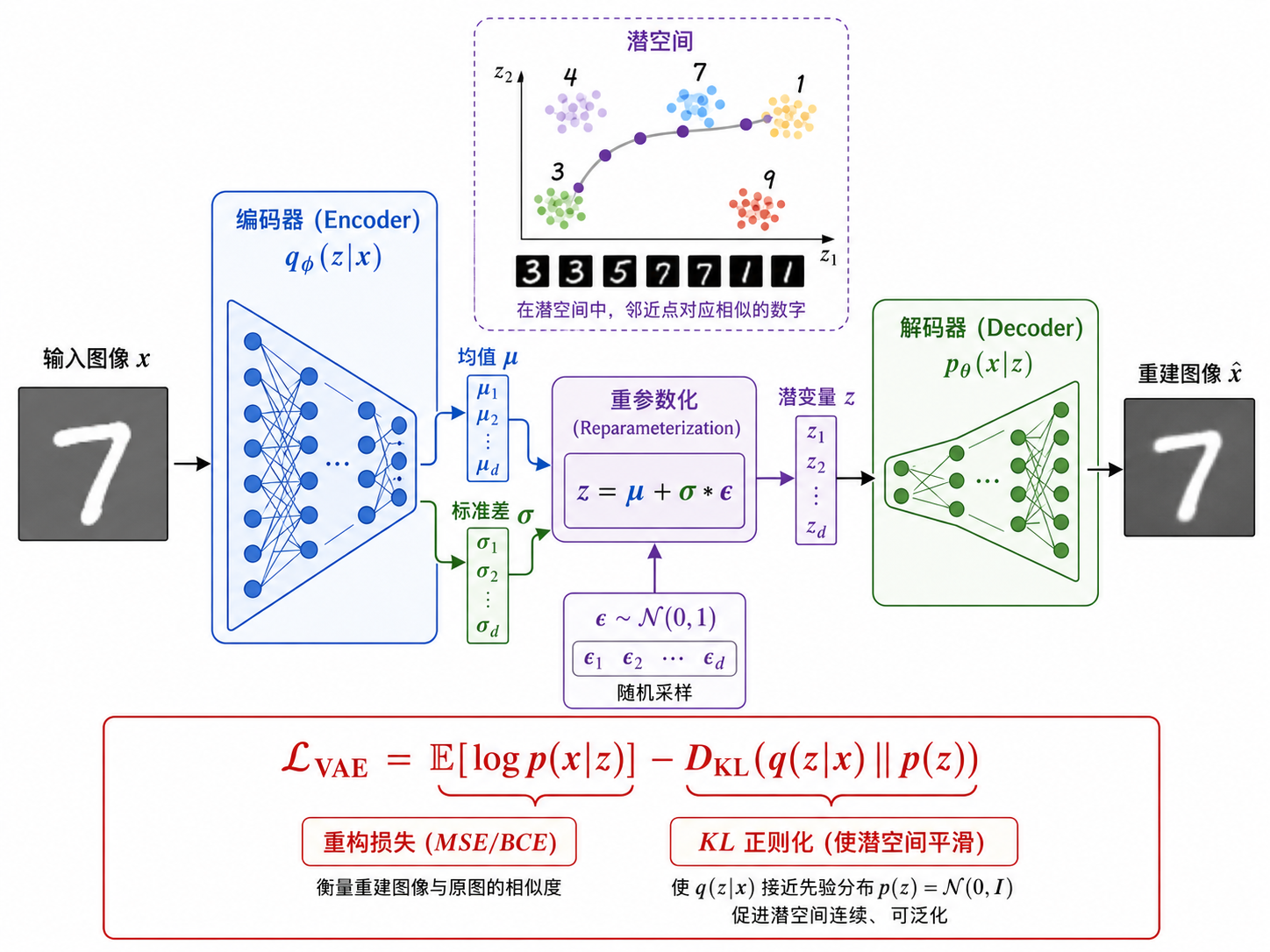
三、VAE:变分自编码器 (2013)
3.1 核心思想:潜变量建模
VAE 假设图像是由一个低维潜变量
由于这个积分在大多数情况下不可解,VAE 转而优化一个下界(ELBO, Evidence Lower Bound):
(Encoder):将输入 编码为潜变量分布参数 (Decoder):从潜变量 重建出图像
3.2 重参数化技巧
VAE 的一个关键创新是重参数化技巧(Reparameterization Trick)。
如果直接从
这样
3.3 VAE 的优缺点
- 优点:潜空间平滑、有结构,两个相近的
值产生相似的图像,可以做插值(interpolation);训练稳定。 - 缺点:生成的图像往往较模糊。这是因为 VAE 优化的是逐像素的 MSE/BCE 重构损失,导致网络倾向于输出像素值的"平均值"——多个可能的模式被平均掉,产生模糊效果。
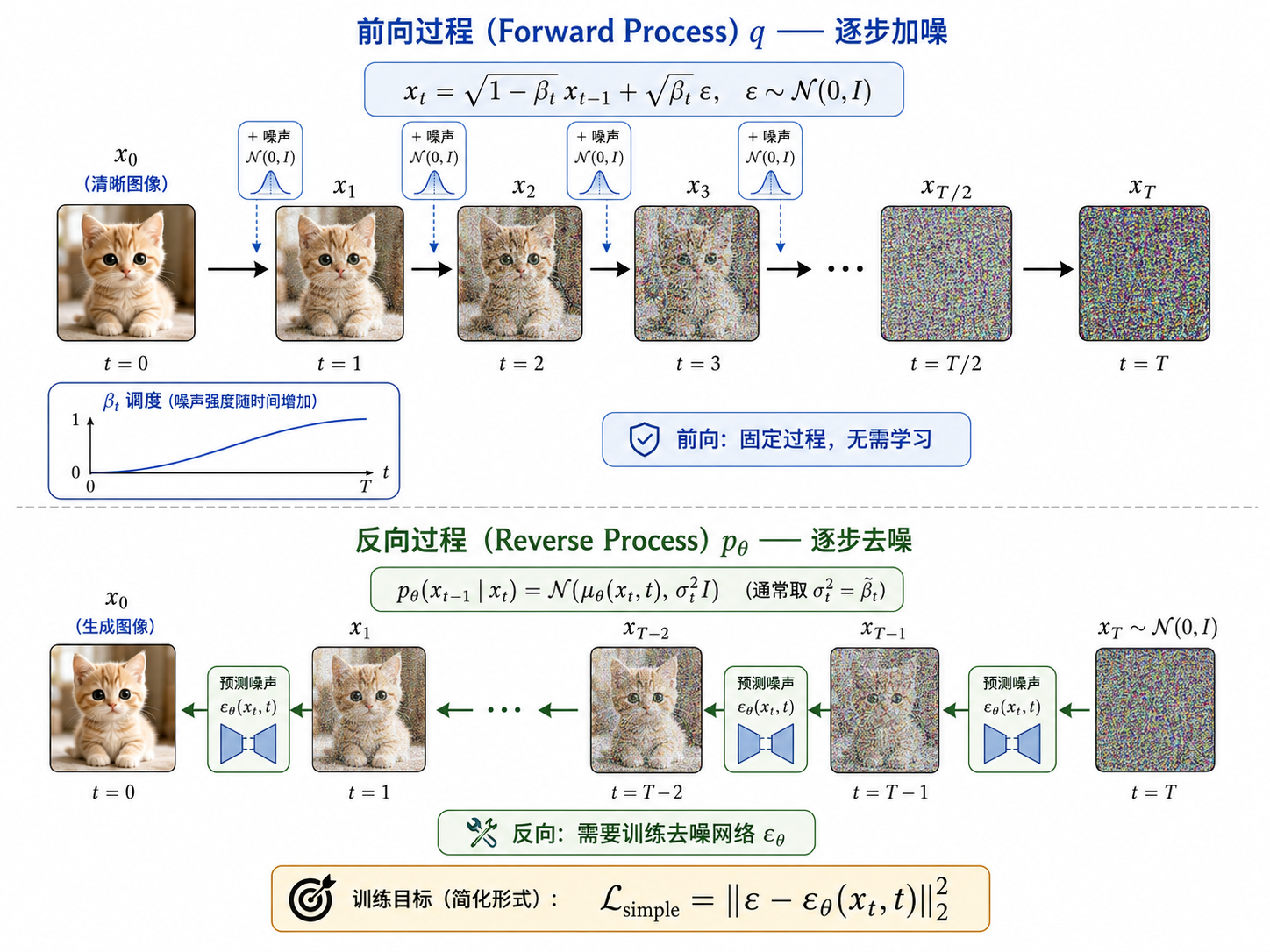
四、扩散模型 (2020+)
4.1 核心思想:渐进去噪
扩散模型的灵感来源于非平衡热力学。它包含两个过程:
前向过程(Forward Process)
其中
反向过程(Reverse Process)
4.2 DDPM 的训练目标
Denoising Diffusion Probabilistic Models (DDPM) 的核心发现是:反向过程的训练可以简化为一个噪声预测任务:
翻译成通俗语言:
- 从训练集中取一张图像
- 随机选一个时间步
- 按照前向过程的公式给
加噪声,得到 - 训练网络
从 中预测出所加的噪声 - 这就是一个简单的回归任务!
4.3 采样(推理)
训练完成后,生成图像的过程是从纯噪声出发,一步步反向去噪:
(纯噪声) - For
: - 输出
(生成的图像)
这个过程通常需要数百甚至上千步,这也是扩散模型生成速度慢的原因。
五、Stable Diffusion (2022)
Stable Diffusion 将扩散模型从三个维度做了关键改进:
- 潜空间扩散(Latent Diffusion):不像 DDPM 那样在像素空间做扩散,而是先训练一个 VAE 将图像压缩到潜空间,在潜空间中做扩散过程。这将计算量降低了一个数量级。
- 文本条件(Text Conditioning):将文本 prompt 通过 CLIP 文本编码器转为嵌入向量,通过交叉注意力(Cross-Attention)注入到去噪 U-Net 中。这使得生成过程可以受文本控制。
- Classifier-Free Guidance:同时训练条件模型和无条件模型,在推理时通过 $ \hat{\epsilon}\theta(x_t, c) = \epsilon\theta(x_t, \varnothing) + w \cdot (\epsilon_\theta(x_t, c) - \epsilon_\theta(x_t, \varnothing)) $ 增强文本控制力度。
六、三种方法的对比
| 特性 | GAN | VAE | Diffusion |
|---|---|---|---|
| 生成质量 | 高(锐利) | 较低(模糊) | 极高(锐利+多样) |
| 多样性 | 低(模式坍塌) | 高(覆盖整个分布) | 高(覆盖整个分布) |
| 训练稳定性 | 极不稳定 | 稳定 | 稳定 |
| 采样速度 | 快(一次前向) | 快(一次前向) | 慢(数百步→数十步) |
| 潜空间 | 无显式潜空间 | 有结构的潜空间 | 固定维度的噪声空间 |
| 理论基础 | 博弈论/极小极大 | 变分推断/ELBO | 随机微分方程/得分匹配 |
三种方法各有千秋:
- GAN 适合需要高速推理且对锐度要求高的场景(如实时视频特效)。
- VAE 适合需要平滑潜空间和结构化的场景(如潜在空间插值、属性编辑)。
- Diffusion 是当前生成质量的标杆(Stable Diffusion, DALL-E 3, Midjourney),但推理速度仍然是瓶颈。

七、本节小结
| 概念 | 一句话 |
|---|---|
| GAN | 生成器与判别器的对抗博弈, |
| 模式坍塌 | GAN 生成器只学会生成少数模式,多样性不足 |
| VAE | 编码器→潜变量→解码器,优化 ELBO = 重构损失 + KL 散度 |
| 重参数化 | |
| 扩散模型前向 | 逐步加高斯噪声,$q(x_t |
| 扩散模型反向 | 学习去噪网络从噪声恢复图像 |
| DDPM 训练 | 预测所加噪声 |
| Stable Diffusion | 在潜空间做扩散 + 文本交叉注意力引导 |
| 采样速度 | GAN/VAE 快(单次前向),Diffusion 慢(迭代去噪) |
至此,我们完成了从图像分类(s10/s11)到目标检测(s12)再到图像生成(s13)的完整旅程。这三个方向构成了计算机视觉的核心支柱:识别、定位、创造。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Goodfellow, I. J., et al. (2014). Generative Adversarial Nets. NeurIPS 2014. (GAN) [arXiv:1406.2661]
- Kingma, D. P. & Welling, M. (2014). Auto-Encoding Variational Bayes. ICLR 2014. (VAE) [arXiv:1312.6114]
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. (DDPM) [arXiv:2006.11239]
- Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. (Stable Diffusion) [arXiv:2112.10752]