s12 目标检测:从 R-CNN 到 YOLO
让计算机回答"图像里有什么,在哪里"——目标检测技术的演进
一、分类、检测、分割
在计算机视觉中,理解图片有三个递进的层次:
| 任务 | 问题 | 输出 |
|---|---|---|
| 图像分类 | 图里是什么? | 一个类别标签 "cat" |
| 目标检测 | 有什么,在哪里? | 多个类别 + 每个的 bounding box |
| 语义分割 | 每个像素是什么? | 逐像素的类别标签 |
| 实例分割 | 每个像素属于哪个物体? | 逐像素的实例标签(区分同类的不同个体) |
目标检测是承上启下的核心任务:它的输出既包含语义信息(类别),也包含空间信息(位置),是整个视觉理解链条中的关键一环。
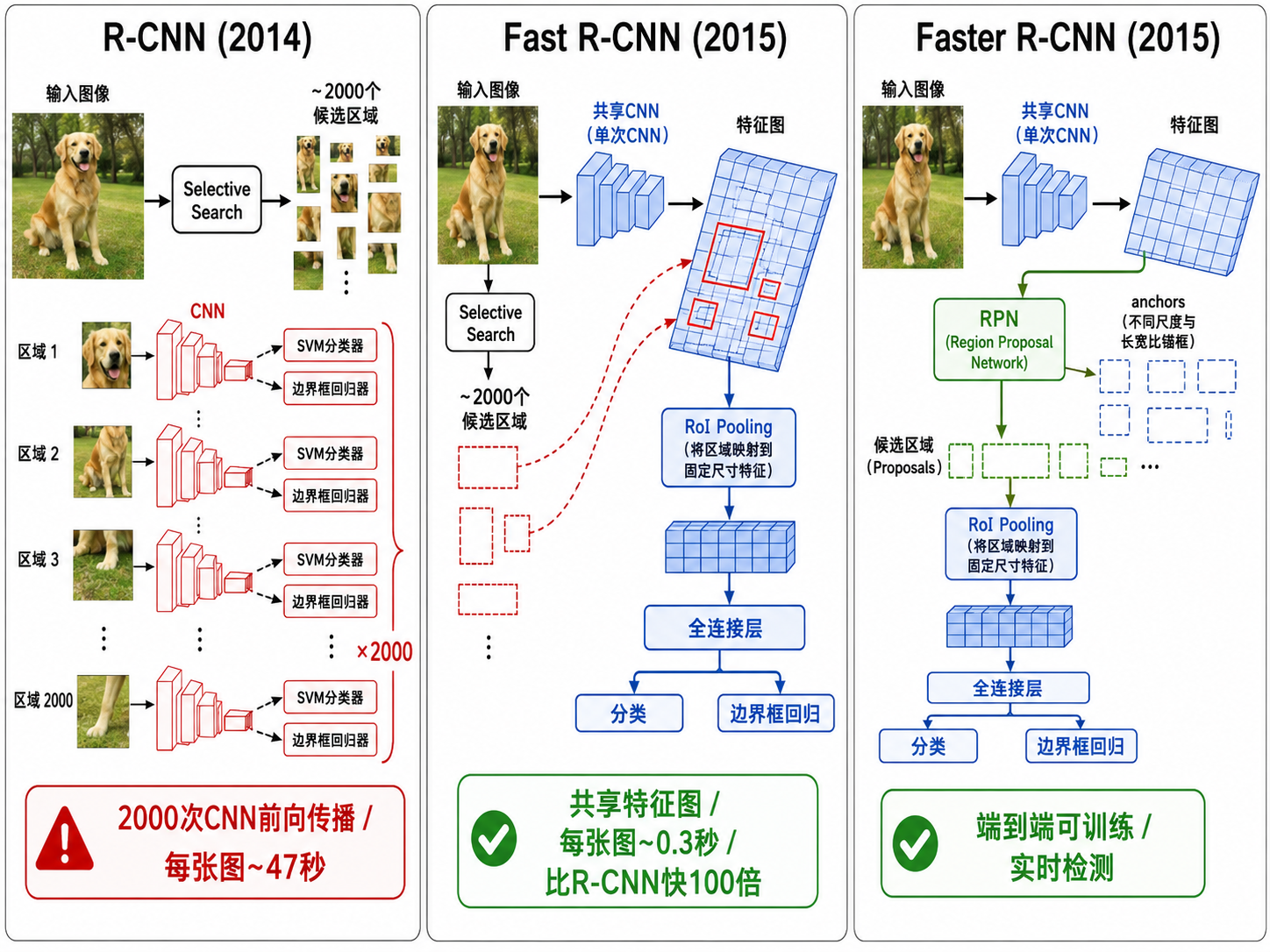
二、R-CNN 家族:两阶段检测器
2.1 R-CNN (2014):朴素的暴力
R-CNN 的思路非常直接:
- Selective Search 在图像中生成约 2000 个候选区域(region proposals)
- 每个候选区域缩放到固定大小(227×227),送入 CNN 提取特征
- 用 SVM 对每个区域的特征向量进行分类
- 用线性回归调整边界框位置(bounding box regression)
问题很明显:2000 次 CNN 前向传播,一张图需要几十秒。CNN 的绝大部分计算被浪费在大量重叠的候选区域上。
2.2 Fast R-CNN (2015):共享特征图
关键改进:整张图只跑一次 CNN,得到一张特征图。然后对每个候选区域,在特征图上做一个 RoI Pooling 操作,提取固定大小的特征向量。
这样,2000 个候选区域共享同一张特征图的 CNN 计算,速度提升了两个数量级。分类器也从 SVM 替换为端到端的 Softmax。
2.3 Faster R-CNN (2015):学会生成候选框
Faster R-CNN 的革命性在于:它把候选区域生成也整合进了神经网络。新增了一个区域提议网络(RPN, Region Proposal Network),直接在特征图上预测候选区域。
RPN 的工作方式:
- 在特征图的每个空间位置放置 k 个锚框(Anchor Boxes)——预设的不同尺度和长宽比的框
- 对每个锚框,RPN 输出:(1) 是否包含物体的分数,(2) 框的位置修正量
- 选取得分最高的 N 个提议框,送入后续的 RoI Pooling 和分类
至此,目标检测完全端到端可训练。
三、锚框(Anchor Boxes)
锚框是目标检测中的重要概念。它们是为每个特征图位置预设的一组参考框,覆盖不同的尺度和长宽比(aspect ratio)。
例如,Faster R-CNN 通常在每个位置设置 9 个锚框:3 种尺度 × 3 种长宽比(0.5, 1.0, 2.0)。网络不直接预测边界框的绝对坐标,而是预测相对于锚框的偏移量:
这种相对编码的好处是:预测值在 0 附近,分布更集中,更容易学习。
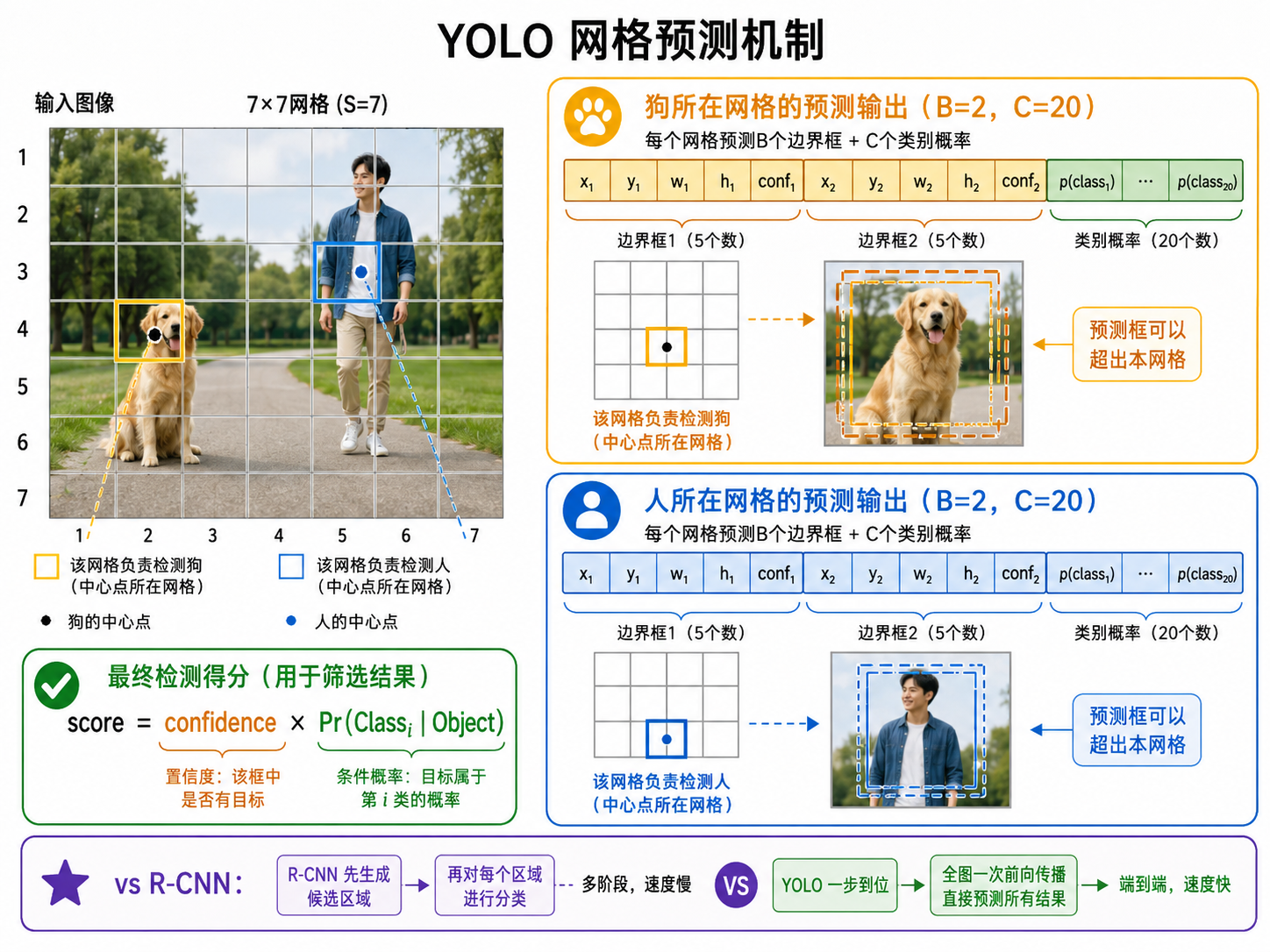
四、YOLO:一步到位
R-CNN 系列是两阶段检测器:先生成候选区域,再分类和精修。YOLO(You Only Look Once)开创了单阶段检测器:一次前向传播,直接输出所有检测结果。
4.1 YOLO 的工作原理
- 将输入图像划分为
的网格(如 ) - 每个网格预测
个边界框(通常 2 个),每个框有 5 个值: - 同时预测
个类别的概率 - 预测的框由"中心点落在哪个网格"的网格负责
输出张量的形状为
4.2 YOLO 的输出格式
对于每个网格的每个预测框:
:边界框中心相对于网格单元左上角的偏移(归一化到 [0, 1]) :边界框宽高相对于整张图的归一化值(归一化到 [0, 1]) :框内包含物体的置信度
对于每个网格:
最终检测得分:
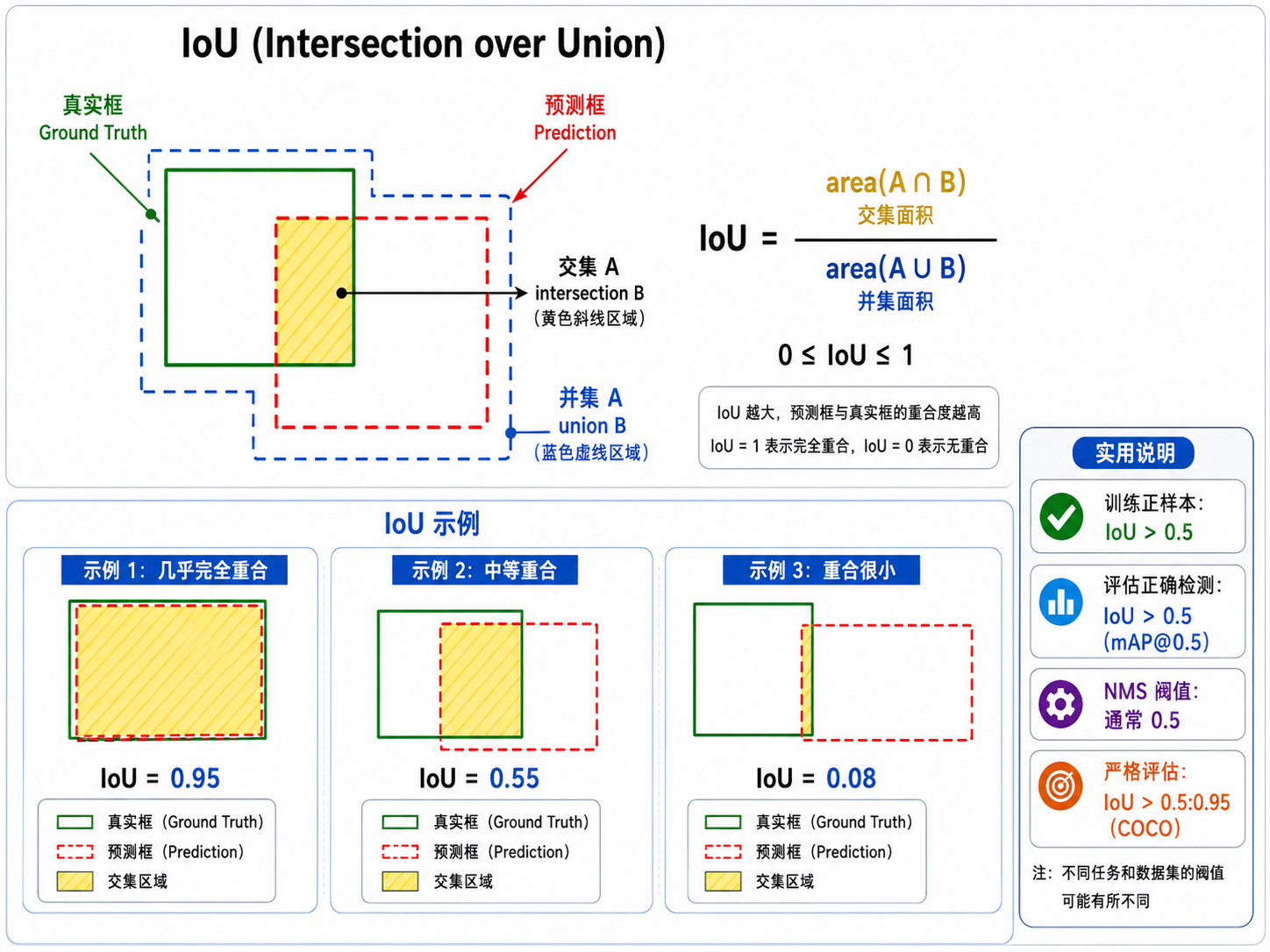
五、IoU(交并比)
交并比 Intersection over Union (IoU) 是衡量两个边界框重叠程度的指标。
设
IoU 取值在
- 训练时:IoU > 0.5 通常认为框包含了目标(正样本)
- 评估时:IoU 用于判断检测是否正确(匹配 ground truth)
- 后处理时:IoU 用于非极大值抑制(NMS)
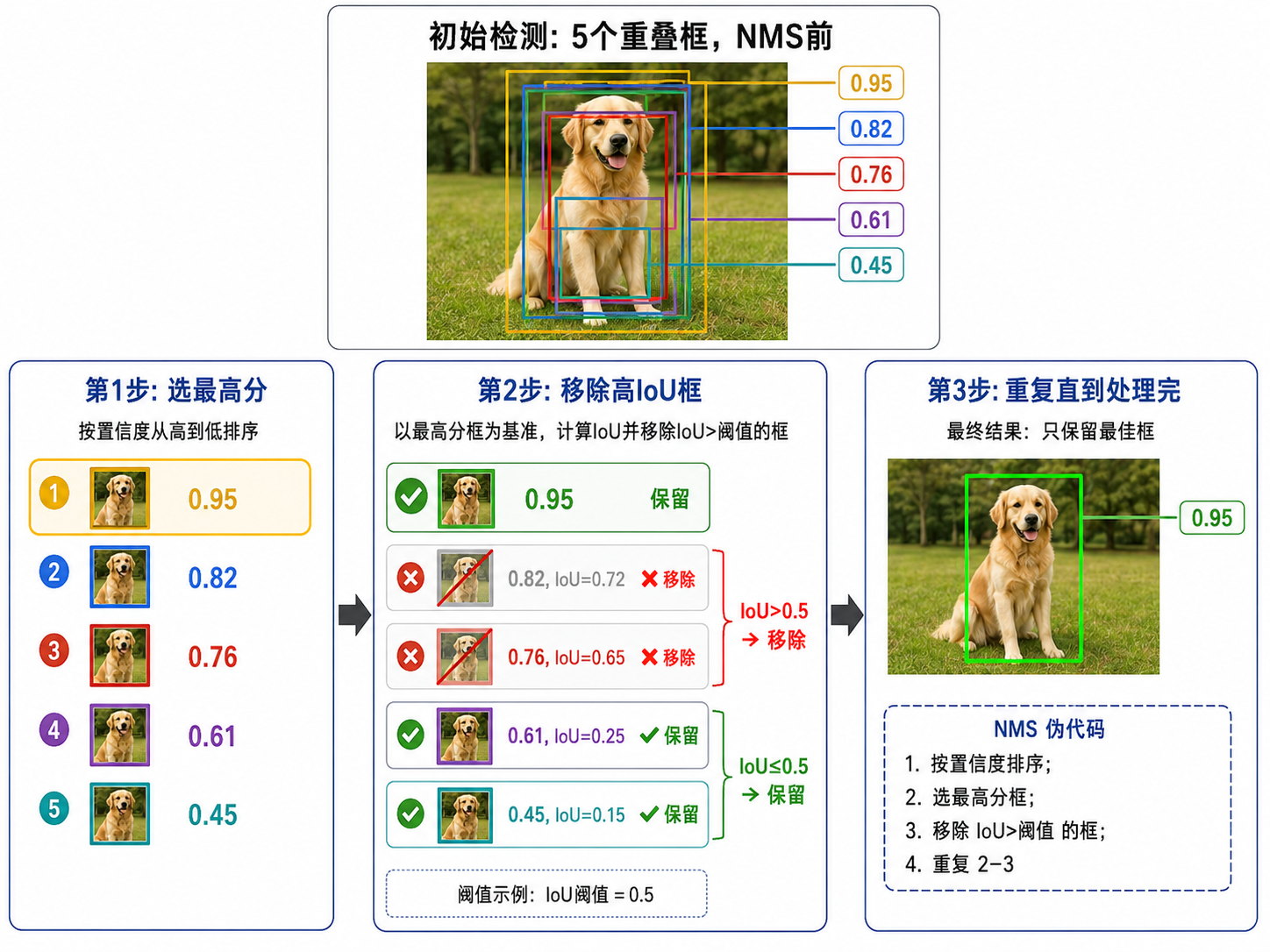
六、NMS(非极大值抑制)
同一个物体可能被多个重叠的边界框检测到。NMS 的作用是去除冗余框,保留最佳的那个。
NMS 算法步骤:
- 将所有检测框按置信度从高到低排序
- 取出置信度最高的框,加入"保留列表"
- 计算该框与其余所有框的 IoU
- 移除所有 IoU > 阈值(如 0.5)的框——它们被认为是同一物体的重复检测
- 重复步骤 2-4,直到没有剩余框
NMS 看似简单,但它对检测最终效果影响极大。IoU 阈值的选择是一个重要的超参数:太小会漏掉真正靠近的不同物体(如拥挤人群中的人),太大会保留太多冗余框。
七、评估指标:mAP(平均精度均值)
目标检测的评估比分类复杂得多,因为它需要同时衡量类别检测的准确性和框定位的精度。
7.1 Precision-Recall 曲线
对于一个类别,按置信度阈值变化绘制 Precision-Recall 曲线。在某个 IoU 阈值下(如 0.5),计算:
- True Positive (TP):IoU > 阈值,且类别正确
- False Positive (FP):类别错误或 IoU < 阈值
- False Negative (FN):漏检的 ground truth
7.2 mAP 的计算
Average Precision (AP):PR 曲线下的面积(11 点插值或积分)。
mean Average Precision (mAP):所有类别的 AP 取平均。
常用的 mAP 变体:
- mAP@0.5:IoU 阈值为 0.5 的 mAP(较宽松)
- mAP@0.5:0.95:IoU 阈值从 0.5 到 0.95 步长 0.05 的 mAP 均值(COCO 标准,更严格)
八、现代检测器
YOLOv8 (2023)
YOLO 系列经历了多次迭代(v1→v3→v5→v8),YOLOv8 代表了最新的单阶段检测技术进步:
- 无锚框(anchor-free)设计,直接预测框中心到边界的距离
- 新的 C2f 模块(改进的特征提取)
- 解耦头(decoupled head):分类和回归用不同的分支
- 多尺度训练和推理
DETR (2020):Transformer 进入检测
DETR (DEtection TRansformer) 将目标检测转化为了一个集合预测问题:
- 使用 CNN backbone 提取特征
- 加上位置编码,送入 Transformer encoder-decoder
- Decoder 一次性输出 N 个预测(包括类别和框),每个预测对应于一个"查询向量"
- 使用匈牙利算法进行二分图匹配,建立预测与 ground truth 的一一对应
DETR 消除了 NMS、锚框等手工设计的组件,是端到端检测的极致体现。缺点是训练收敛慢(需要数百个 epoch)。
九、本节小结
| 概念 | 一句话 |
|---|---|
| 目标检测 | 同时回答"是什么"和"在哪里" |
| R-CNN | 候选区域 → CNN 逐一分类(慢,2000 次前向) |
| Fast R-CNN | 共享特征图 + RoI Pooling(快 100 倍) |
| Faster R-CNN | RPN 学会生成候选区域(完全端到端) |
| Anchor Box | 预设参考框,网络预测相对偏移 |
| YOLO | 单阶段,S×S 网格直接输出所有检测结果 |
| IoU | 衡量两个框重叠程度:交集 / 并集 |
| NMS | 去除冗余框:保留置信度最高的,移除高 IoU 的 |
| mAP | 多类别平均精度:PR 曲线下面积的平均值 |
下一节 s12b Vision Transformer 将展示 Transformer 如何颠覆计算机视觉——用自注意力替代卷积,开创图像理解的新范式。之后 s13 图像生成 将探讨如何让模型"创造"图像。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. CVPR 2014. (R-CNN) [arXiv:1311.2524]
- Girshick, R. (2015). Fast R-CNN. ICCV 2015. [arXiv:1504.08083]
- Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NeurIPS 2015. [arXiv:1506.01497]
- Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection. CVPR 2016. (YOLO) [arXiv:1506.02640]
- Carion, N., et al. (2020). End-to-End Object Detection with Transformers. ECCV 2020. (DETR) [arXiv:2005.12872]