s10 CNN 核心原理:卷积与感受野
从零理解卷积操作 —— 为什么卷积神经网络能"看懂"图像
一、为什么用卷积处理图像?
传统的全连接神经网络处理图像时,面临两个根本问题。假设一张
然而,卷积操作天然地利用了图像的三个重要先验,完美解决了这些问题:
1. 平移不变性(Translation Invariance)
一只猫出现在图像的左上角还是右下角,它都是猫。卷积核在图像上滑动,无论目标移动到哪个位置,同一个卷积核都能检测到它。这是卷积的核心设计理念——权值共享:一个
2. 局部连接(Local Connectivity)
图像中相距较远的像素之间通常没有直接的语义关联。一个边缘检测器只需要看局部的
3. 参数共享(Parameter Sharing)
同一个特征(如"水平边缘")可能在图像的任意位置出现。卷积核在整个图像上共享权重,使得检测"水平边缘"只需要学一组参数,而非为每个位置单独学习。
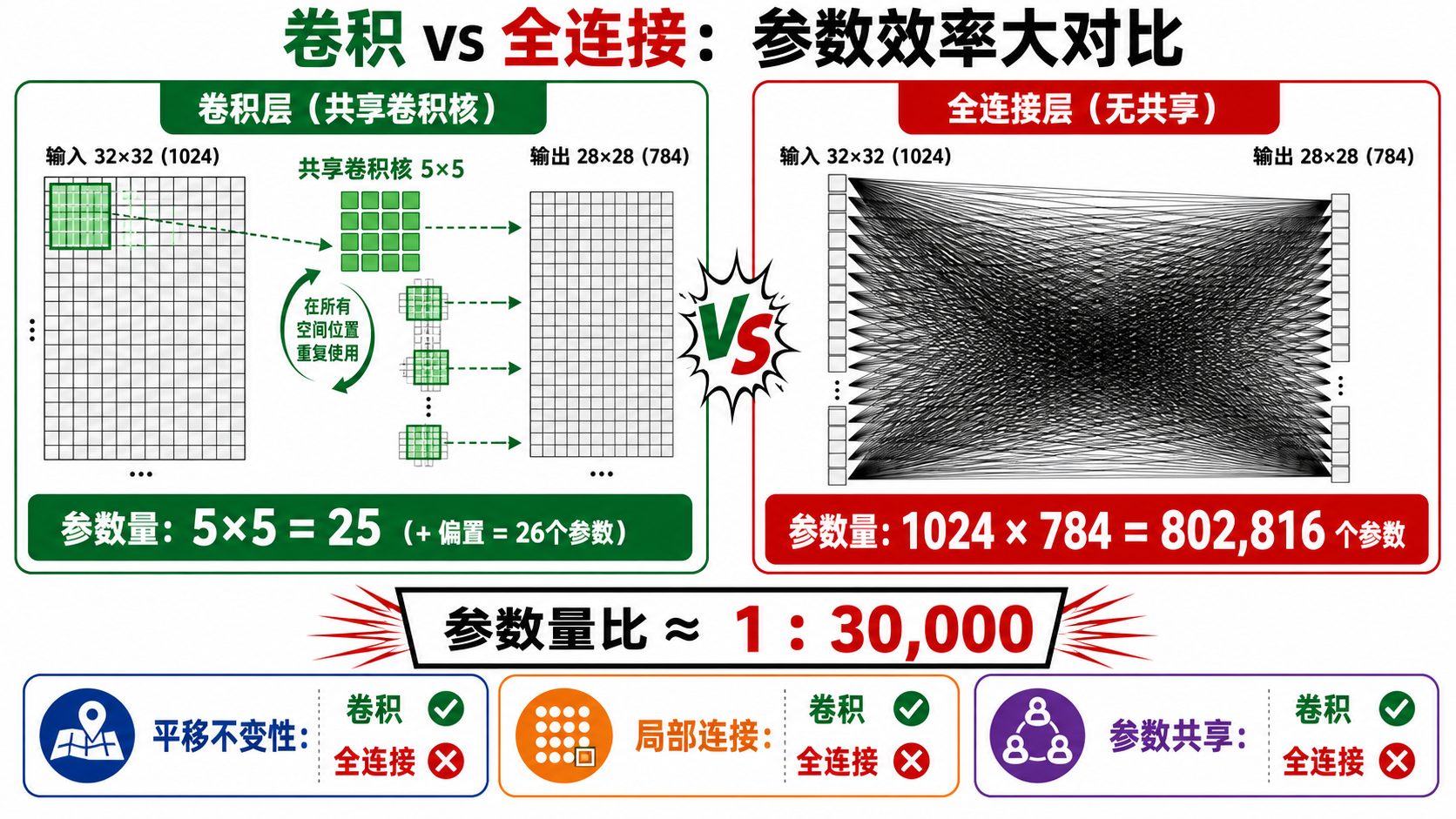
一句话总结:卷积层将全连接层的
参数量降到了 ,其中 是卷积核大小(通常 3 或 5),与输入尺寸无关。
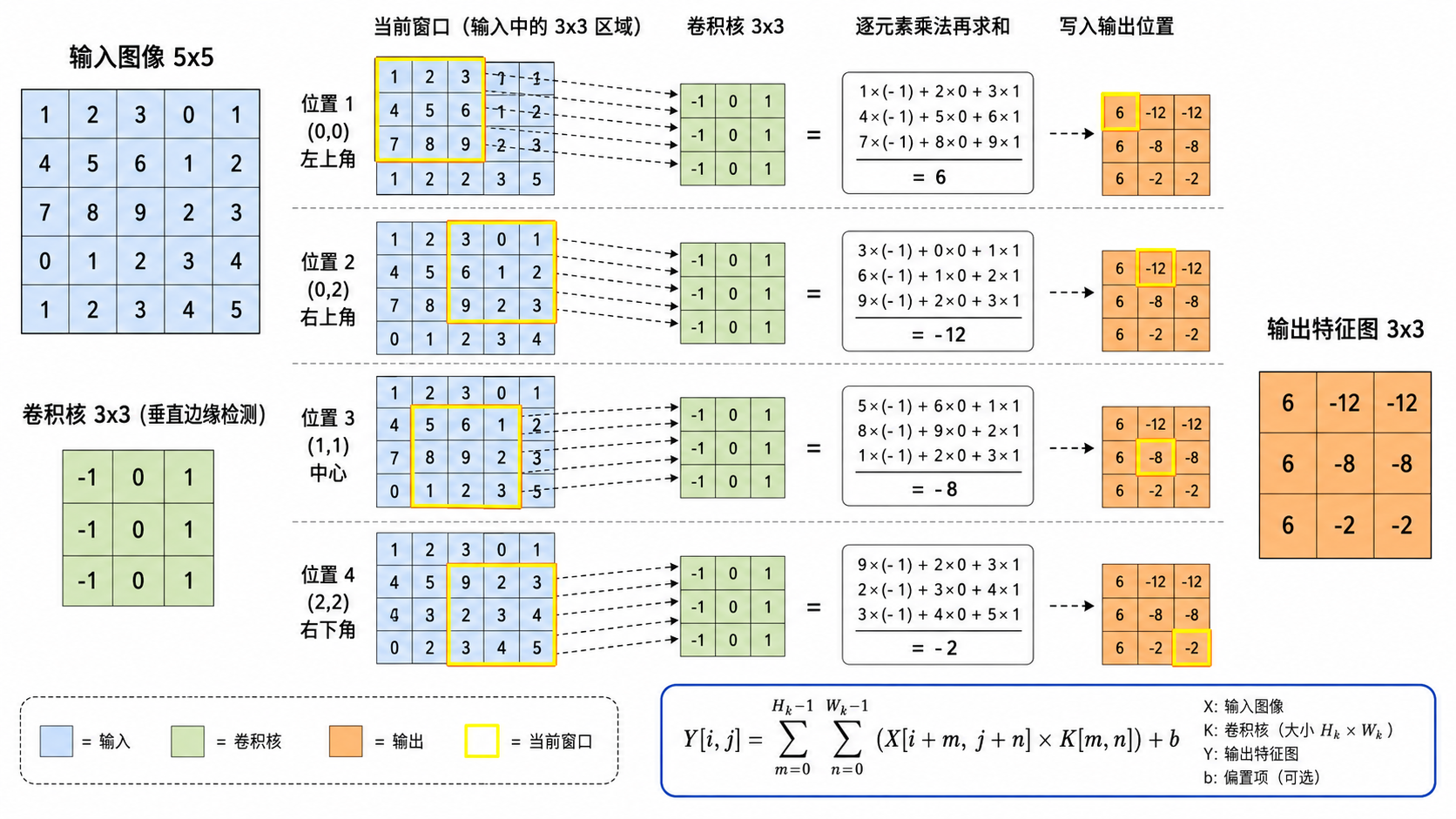
二、卷积操作:从数学到直观
2.1 二维卷积的数学定义
给定输入图像
其中
2.2 直观理解:滑动窗口
卷积核就像一个"探测器",在输入图像上从左到右、从上到下滑动。每次停在一个位置,就做一次逐元素乘法再求和:
- 把
的卷积核"盖"在图像的 区域上 - 对应位置的 9 对数字相乘
- 把 9 个乘积加起来,得到输出特征图上的一个像素值
- 卷积核向右滑动一格(步长),重复以上过程
这个过程类似于信号处理中的互相关(Cross-Correlation)操作——深度学习中的"卷积"严格来说是互相关,因为卷积核没有翻转。但在实际使用中,大家统一称之为卷积。
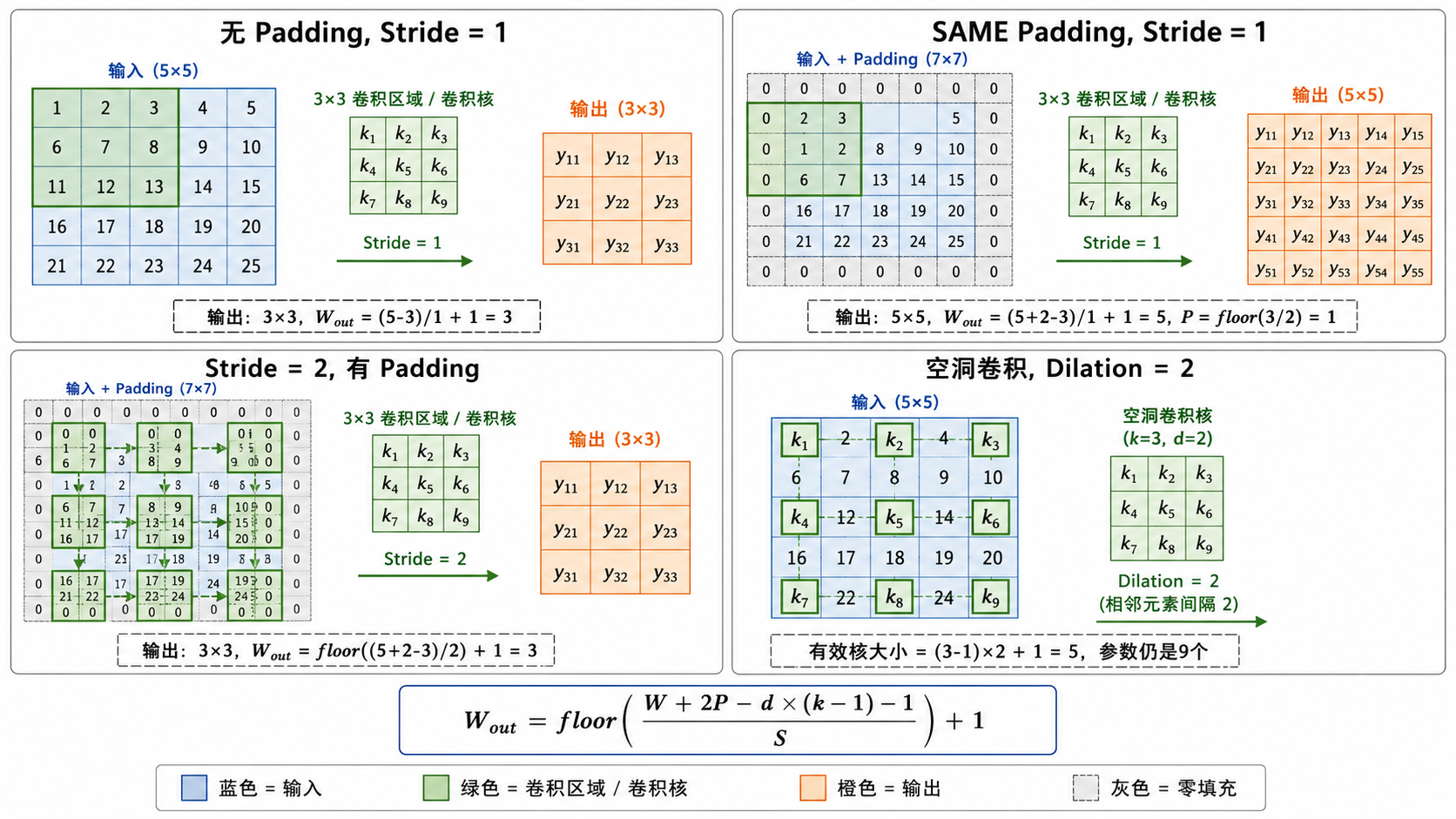
三、Padding、Stride 与输出尺寸
3.1 Padding(填充)
如果不做 padding,每次卷积都会使输出尺寸缩小。对于
- VALID padding(无填充):输出尺寸为
- SAME padding(等尺寸):在输入边缘填充
圈零值,使得输出尺寸与输入相同:
SAME padding 的命名非常直观——输入输出保持相同尺寸。对于
3.2 Stride(步长)
步长
3.3 Dilation(空洞卷积)
空洞卷积通过在卷积核元素之间插入"空洞"(零值)来扩大感受野,而不增加参数数量。对于 dilation rate
通用输出尺寸公式:对于输入尺寸
当
四、池化(Pooling):降维与不变性
池化层不包含可学习的参数,它通过固定的下采样操作缩小特征图的尺寸。
4.1 最大池化(Max Pooling)
在
输入 2×2 区域: 最大池化输出:
[1, 3] 9
[7, 9]4.2 平均池化(Average Pooling)
在
4.3 池化的作用
- 降维:
池化(stride=2)将特征图尺寸减半,减少后续层的计算量 - 平移不变性:输入微小平移时,池化后的输出可能完全不变——这有助于分类任务的鲁棒性
- 增大感受野:不需要增加卷积核大小,就能让深层神经元看到更大的输入区域
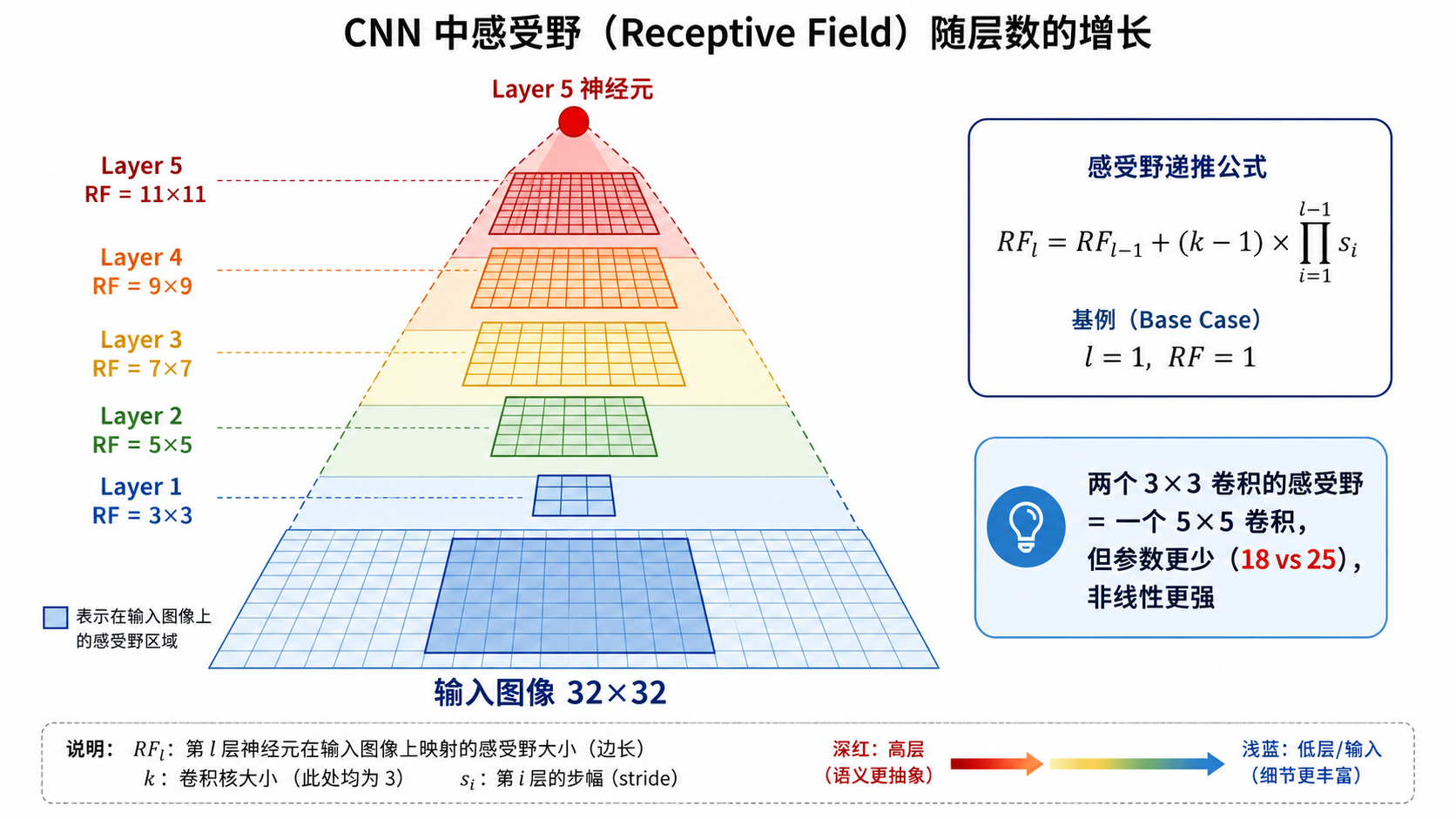
五、感受野(Receptive Field)
5.1 什么是感受野?
在 CNN 中,某一层特征图上的一个神经元的值,由输入图像上的某一区域决定。这个区域就是该神经元的感受野。
- 第 1 层(
卷积):每个神经元看到输入图像的 区域 - 第 2 层(再做一个
卷积):每个神经元看到输入图像的 区域 - 第 3 层:感受野扩大到
5.2 感受野的递推公式
设第
其中
直觉:每加一层卷积,感受野以
为步长线性增长(在原始图像尺度上)。而池化的步长会加速感受野的扩张——一个 池化(stride=2)会直接使感受野翻倍。
5.3 感受野为什么重要?
- 分类任务:高层神经元需要足够大的感受野来覆盖整个目标物体
- 语义分割:需要同时拥有大感受野(全局上下文)和小感受野(精细边界)
- 目标检测:需要在不同尺度上检测不同大小的目标
小卷积核堆叠 vs 大卷积核:两个
卷积(感受野 ,参数 )可以替代一个 卷积(感受野 ,参数 ),且非线性更强。这就是 VGG 的设计哲学。
六、多通道卷积
真实图像有多个通道(如 RGB 三通道),而 CNN 的每一层也会输出多个特征图(多个通道)。
6.1 输入通道→输出通道
一个卷积层的卷积核是 3D 的:形状为
对于第
符号
换句话说,一个
6.2 1×1 卷积(Pointwise Convolution)
- 通道降维/升维:将 256 通道的输入降到 64 通道,大幅减少后续
卷积的计算量 - 跨通道信息融合:在每个空间位置上独立地混合通道信息,等价于逐像素的全连接
- 增加非线性:
Conv + ReLU 相当于在不增加感受野的情况下增加网络的表达能力
这是 GoogLeNet Inception 模块和 ResNet Bottleneck 设计的核心工具。
七、卷积层的计算量与参数量
对于一个卷积层,设输入大小为
参数量
最后的
计算量(FLOPs)
每次卷积有
因子 2 是因为每次乘法通常伴随一次加法(Multiply-Add 算一次)。
对比全连接层:假设输入为
的展开向量,全连接到 需要约 个参数——是卷积层的 倍。对于 的输入,这个倍数轻松达到成百上千。
八、Im2Col:卷积的矩阵乘法实现
在底层实现中,卷积通常被转化为矩阵乘法(GEMM)来利用 GPU 的并行计算能力。这个转化过程叫做 im2col(image to column):
- 提取输入中每一个"将被卷积核覆盖的小块"(patches),每个 patch 的大小是
- 将所有 patches 排列成一个矩阵
,形状为 - 将卷积核展开成矩阵
,形状为 - 做一次矩阵乘法:
,再 reshape 为输出形状
这就是为什么现代深度学习框架中的卷积操作能跑得这么快——底层调用的是高度优化的 GEMM 库(如 cuBLAS、MKL)。
九、本节小结
| 概念 | 一句话 |
|---|---|
| 卷积的动机 | 利用图像的平移不变性、局部连接和参数共享,大幅降低参数量 |
| 卷积操作 | 卷积核在输入上滑动,每次做逐元素乘法再求和 |
| Padding | 在输入边缘填零,控制输出尺寸(VALID 无填充,SAME 保持尺寸) |
| Stride | 卷积核滑动步长,控制下采样程度 |
| 池化 | 无参数的下采样(最大池化保留显著特征,平均池化保留整体信息) |
| 感受野 | 深层神经元对应到原始输入上的区域大小,随层数单调增长 |
| 多通道 | |
| 1×1 卷积 | 逐像素的跨通道线性混合,用于升降维和通道交互 |
| 计算量 |
下一节 s11 经典架构演进 将展示这些基本组件如何被组装成 LeNet、AlexNet、VGG、ResNet 等里程碑式的网络架构,以及它们各自的创新点在哪里。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE. (LeNet-5) [doi:10.1109/5.726791]
- Fukushima, K. (1980). Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition. Biological Cybernetics. (CNN 前身)