ml12 EM算法与高斯混合模型
当数据中有"看不见的变量",如何估计模型参数?EM 算法给出了一个优雅的迭代答案——而 GMM 就是 EM 最经典的应用。
一、EM 算法:从"鸡生蛋蛋生鸡"到迭代求解
1.1 问题设定
假设我们有观测数据
这个求和(或积分)在
1.2 EM 的核心思想
EM 算法通过引入辅助函数(变分下界)来解耦
E 步(Expectation):用当前参数
M 步(Maximization):最大化 Q 函数得到新参数:
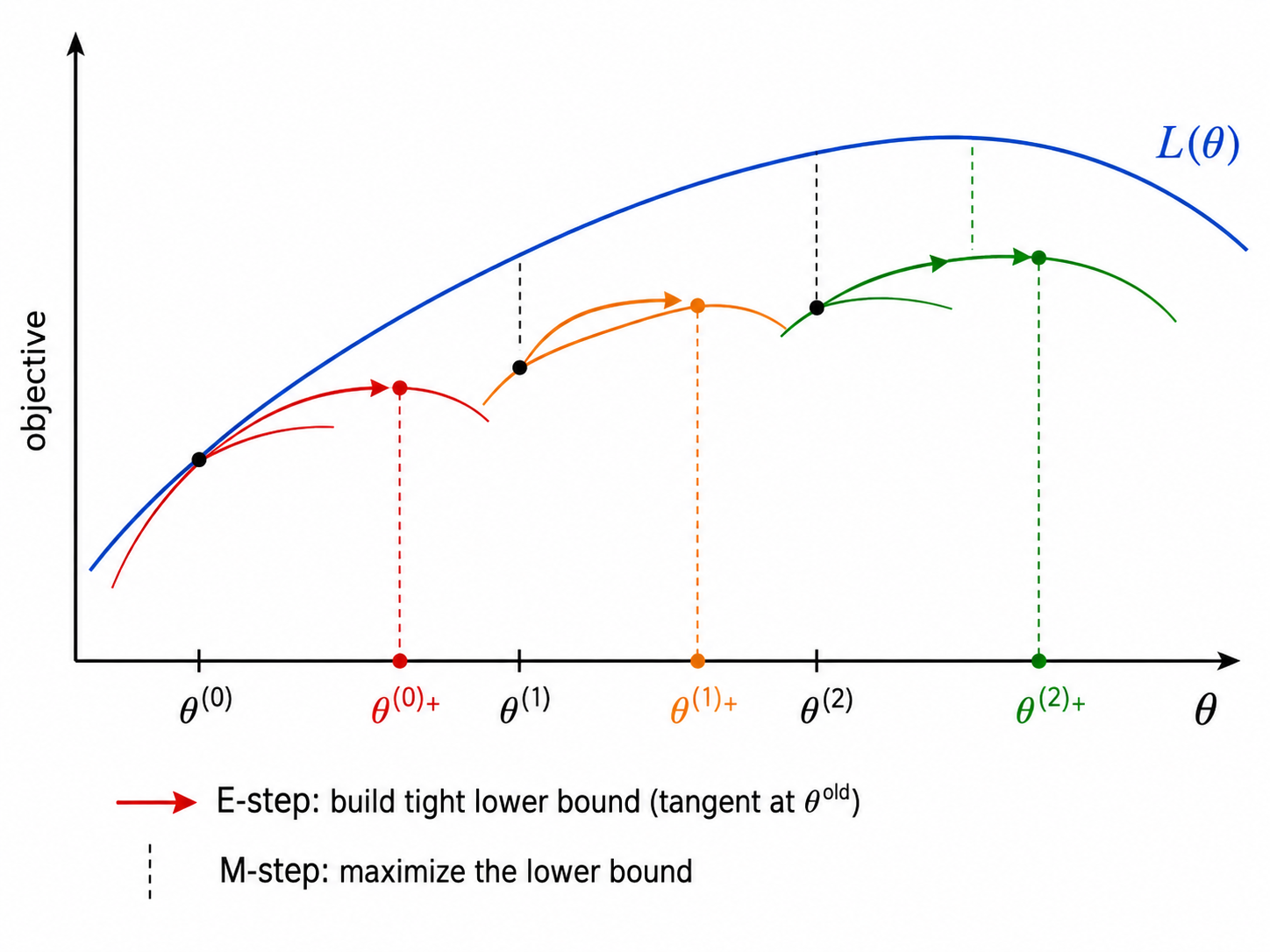
直觉:如果隐变量已知,参数估计很简单(直接最大似然)。但隐变量未知。EM 的策略是——用当前参数"猜测"隐变量的分布(E 步),然后在这个猜测下更新参数(M 步),反复迭代直到收敛。这正是"先有鸡还是先有蛋"的迭代解法。
1.3 Jensen 不等式与 ELBO
EM 算法的单调性可以通过 Jensen 不等式来证明。对于任意分布
右边称为 ELBO(Evidence Lower BOund)。当
E 步:令
EM 算法保证
二、高斯混合模型(GMM)
2.1 模型定义
GMM 假设数据由
其中:
:混合系数(mixing coefficient), , :第 个高斯成分的均值向量 :第 个高斯成分的协方差矩阵
隐变量
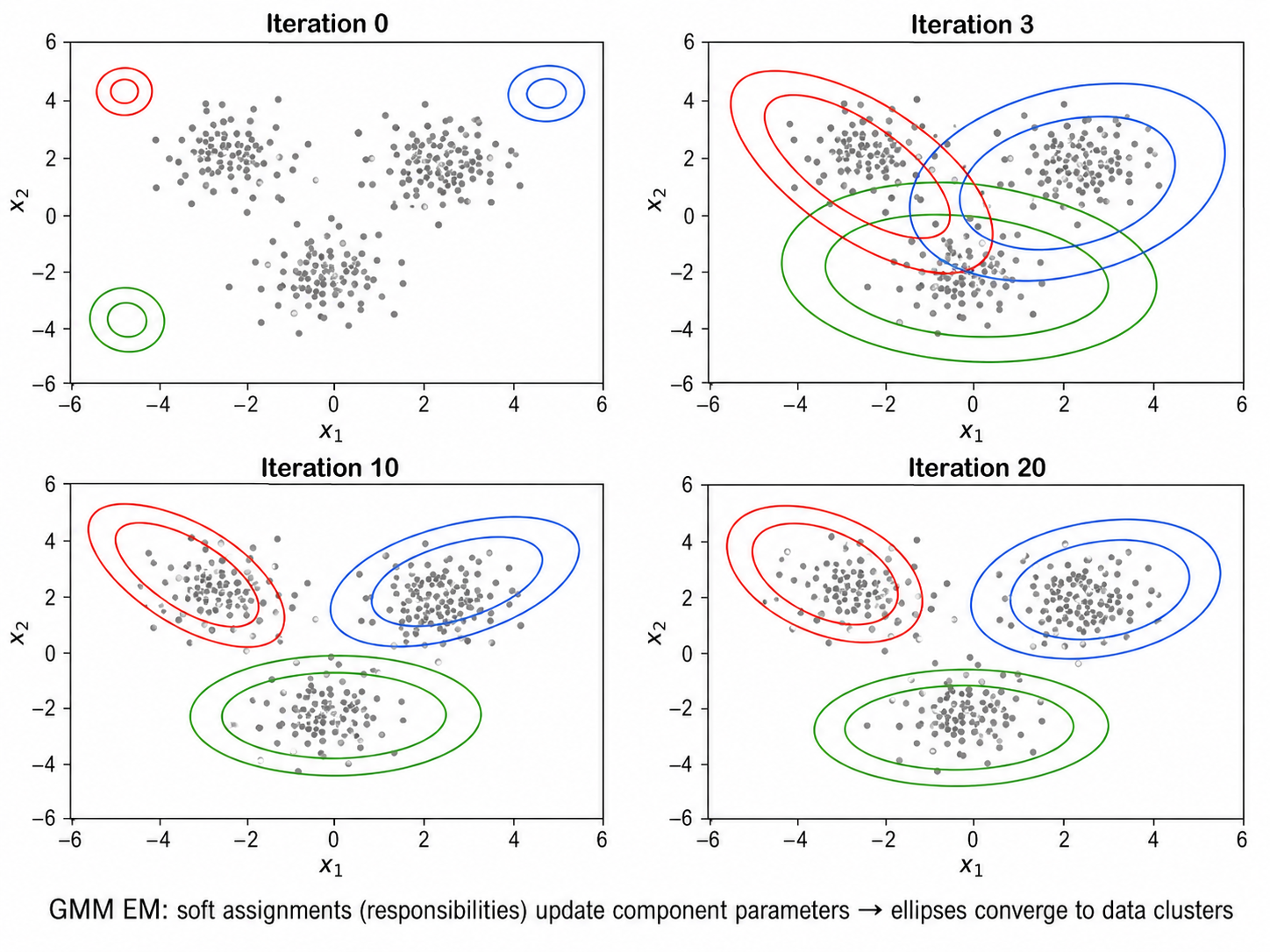
2.2 GMM 的 EM 推导
E 步:计算责任(responsibilities)
M 步:更新参数
直觉:软计数 vs 硬计数。传统的最大似然估计中,如果知道每个样本属于哪个成分,参数就是简单的样本均值和协方差。GMM 的 M 步用"软分配"(责任
而非 0/1 分配)来替代——每个样本"部分地"属于每个成分,贡献按其责任加权。
2.3 K-Means 作为 GMM 的硬分配极限
K-Means 可以看作 GMM 的一个特殊情况:
- 所有协方差
(球形且各向同性) (方差趋于零) - 责任
(软分配退化为硬分配)
在这个极限下,GMM 的 EM 算法退化为 K-Means 的 Lloyd 算法——分配步(E 步)变为找最近质心,更新步(M 步)变为求簇内均值。
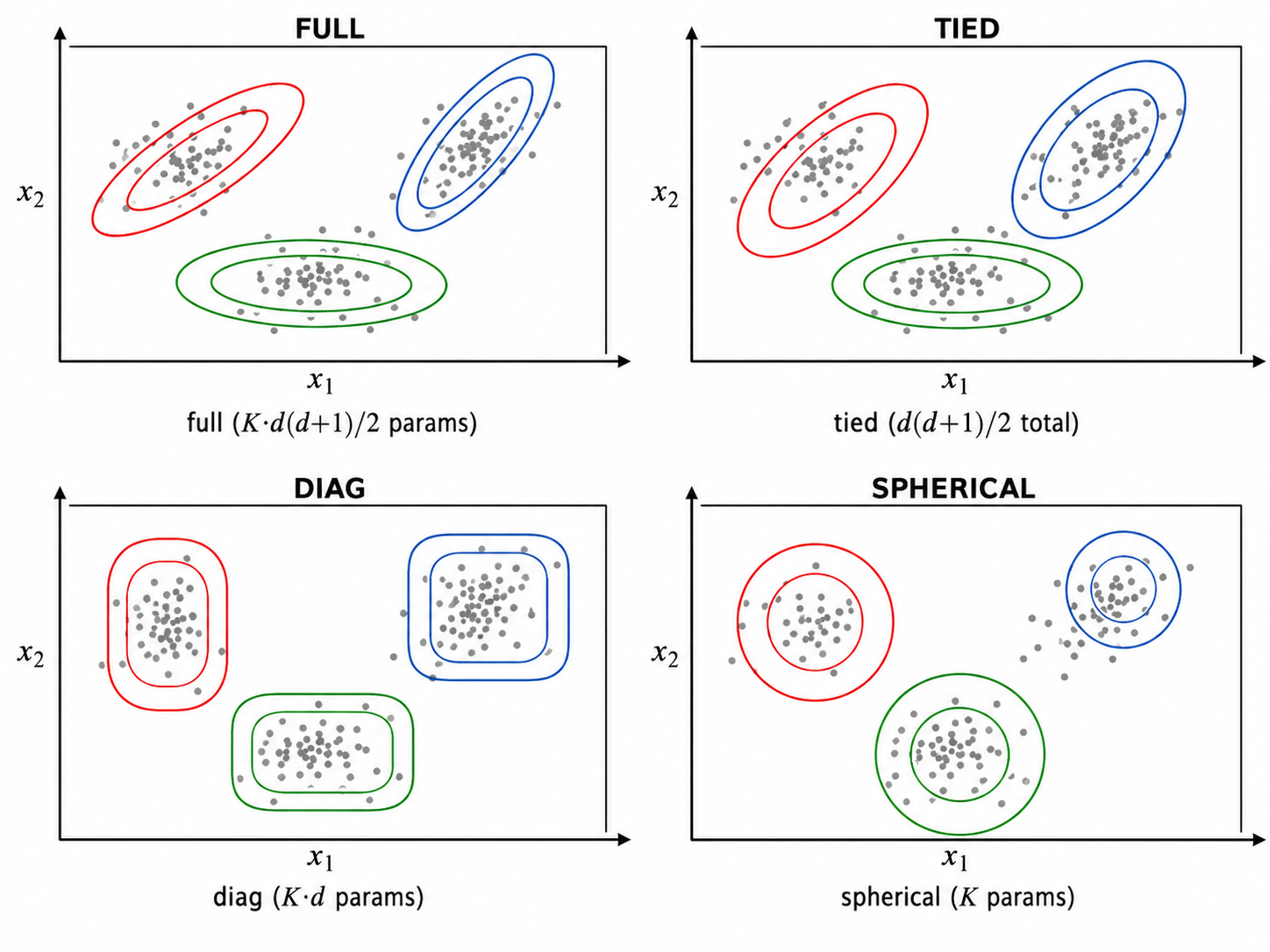
三、协方差类型的选择
GMM 允许对协方差矩阵施加不同约束,以控制模型复杂度和计算开销:
| 协方差类型 | 约束 | 参数数(d 维) | 几何形状 |
|---|---|---|---|
| full | 无约束 | 任意方向的椭圆 | |
| tied | 所有成分共享 | 同形状、同方向的椭圆 | |
| diag | 对角矩阵 | 轴对齐的椭圆 | |
| spherical | 正圆 |
选择建议:数据量大、维度高时,先用 spherical 或 diag 减少参数;数据较少、需要精细建模时用 full。tied 在数据各成分形状相似时有效。
四、模型选择:AIC 与 BIC
在 GMM 中,成分数
4.1 AIC(赤池信息准则)
其中
4.2 BIC(贝叶斯信息准则)
BIC 对参数数量的惩罚比 AIC 更重(
4.3 使用指导
AIC 选 K 通常偏大(倾向复杂模型)→ 适合预测任务
BIC 选 K 通常适中 → 适合模型解释和结构发现
两者不一致时 → 取两者的"共识区间"内的 K五、GMM 的实用考量
5.1 初始化
EM 对初始化敏感,可能收敛到局部最优:
- K-Means 初始化:用 K-Means 的聚类结果初始化
和 - 多次随机初始化:运行多次,选择似然最高的结果
- 实践中结合两者:K-Means 提供一个好起点,多次运行增加找到更优解的概率
5.2 协方差矩阵的奇异性
当某个成分的样本过少或数据在某个方向上完全共线时,协方差矩阵可能奇异(不可逆)。解决方法:
- 使用 regularization(协方差正则化):
- 限制协方差类型(如 diag 或 spherical)可天然避免奇异
- 增加最小样本数要求
5.3 收敛判断
EM 通常在以下条件之一满足时停止:
- 对数似然的相对变化
(如 ) - 达到最大迭代次数
注意 EM 的收敛可能是缓慢的(尤其在参数空间的平坦区域),有时需要数百次迭代。
六、GMM vs 其他聚类方法
| 特性 | K-Means | GMM | DBSCAN |
|---|---|---|---|
| 软分配 | 否(硬) | 是(概率) | 否(硬) |
| 簇形状 | 球形 | 椭圆 | 任意 |
| 概率输出 | 否 | 是(每个样本属于每簇的概率) | 否 |
| 对异常值 | 敏感 | 中等 | 鲁棒 |
| 参数 | K | K + 协方差类型 | eps, minPts |
| 模型复杂度 | 低 | 中-高 | 低-中 |
本章总结
| 概念 | 一句话 |
|---|---|
| EM 算法 | E 步计算期望(Q 函数),M 步最大化参数,交替迭代保证似然单调递增 |
| Jensen's Inequality | 凸函数下 |
| ELBO | 对数似然的下界,EM 等价于交替最大化 ELBO |
| GMM | |
| 责任 | 样本 |
| M 步公式 | 加权均值/协方差/混合系数更新 |
| K-Means vs GMM | GMM 当 |
| AIC / BIC | 似然 + 参数惩罚,用于选择 K |
| 协方差类型 | full / tied / diag / spherical 四种约束 |
| 初始化 | K-Means 初始 + 多次随机运行,避免局部最优 |
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. JRSS-B, 39(1), 1-38. [doi:10.1111/j.2517-6161.1977.tb01600.x]
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. Chapter 9: Mixture Models and EM. [web]
- Akaike, H. (1974). A New Look at the Statistical Model Identification. IEEE TAC, 19(6), 716-723. [doi:10.1109/TAC.1974.1100705]
- Schwarz, G. (1978). Estimating the Dimension of a Model. The Annals of Statistics, 6(2), 461-464. [doi:10.1214/aos/1176344136]
- McLachlan, G. J. & Peel, D. (2000). Finite Mixture Models. Wiley. [doi:10.1002/0471721182]