从线性回归理解「学习」
1. 什么是回归?
回归(Regression)是监督学习中预测连续数值的任务。与分类(预测离散类别)不同,回归的输出是一个实数。
以一个日常例子来理解:你想预测北京的房价。你有以下特征(features):
:房屋面积(平方米) :卧室数量 :距离地铁站的距离(米)
你的目标是预测一个连续值
回归问题的数学描述:
回归是机器学习中最基础也是最重要的任务之一。理解了线性回归,你就能理解「学习」的本质——模型如何在数据驱动下自动调整参数,以最小化预测误差。
2. 线性模型:最朴实但最有力的假设
2.1 标量形式
最简单的线性模型假设输出
其中:
(读作 y-hat)是模型的预测值 是输入特征 是权重(weight),决定了 每变化 1 个单位时, 变化多少 是偏置(bias),当 时的预测值
2.2 多特征推广
当有
2.3 矩阵形式(向量化)
将所有参数和特征写成向量,可以得到简洁的矩阵形式:
对于整个数据集(
其中
为了进一步简化,我们可以把偏置
这种紧凑形式在大规模计算(如深度学习框架中)非常有用。
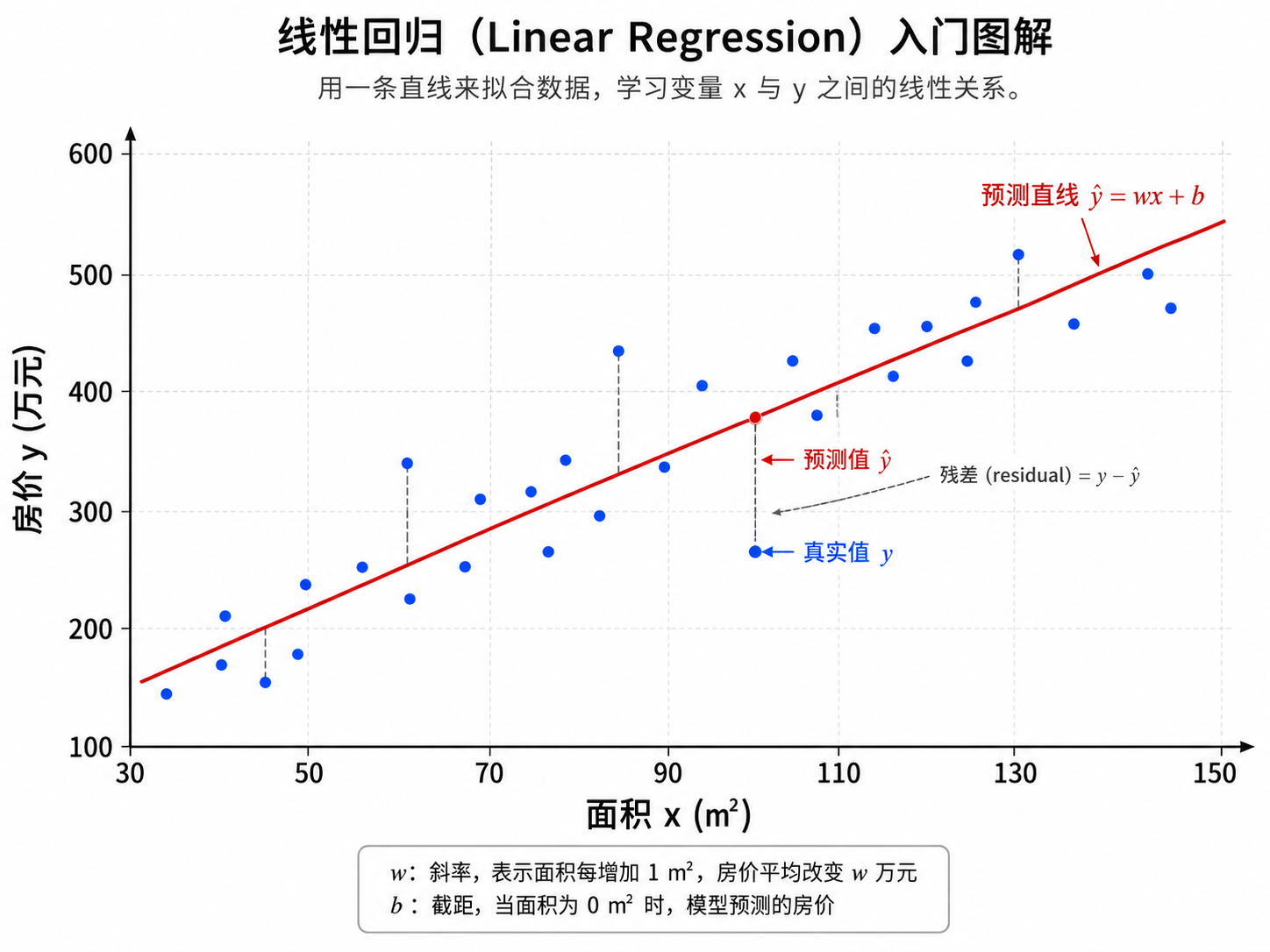
3. 损失函数:如何衡量「好」与「坏」
有了模型,我们需要一种方式来量化模型的预测到底有多「好」或有多「差」。这就是**损失函数(Loss Function)**的作用。
3.1 均方误差(MSE)
在线性回归中,最常用的是均方误差(Mean Squared Error, MSE):
用矩阵形式表示:
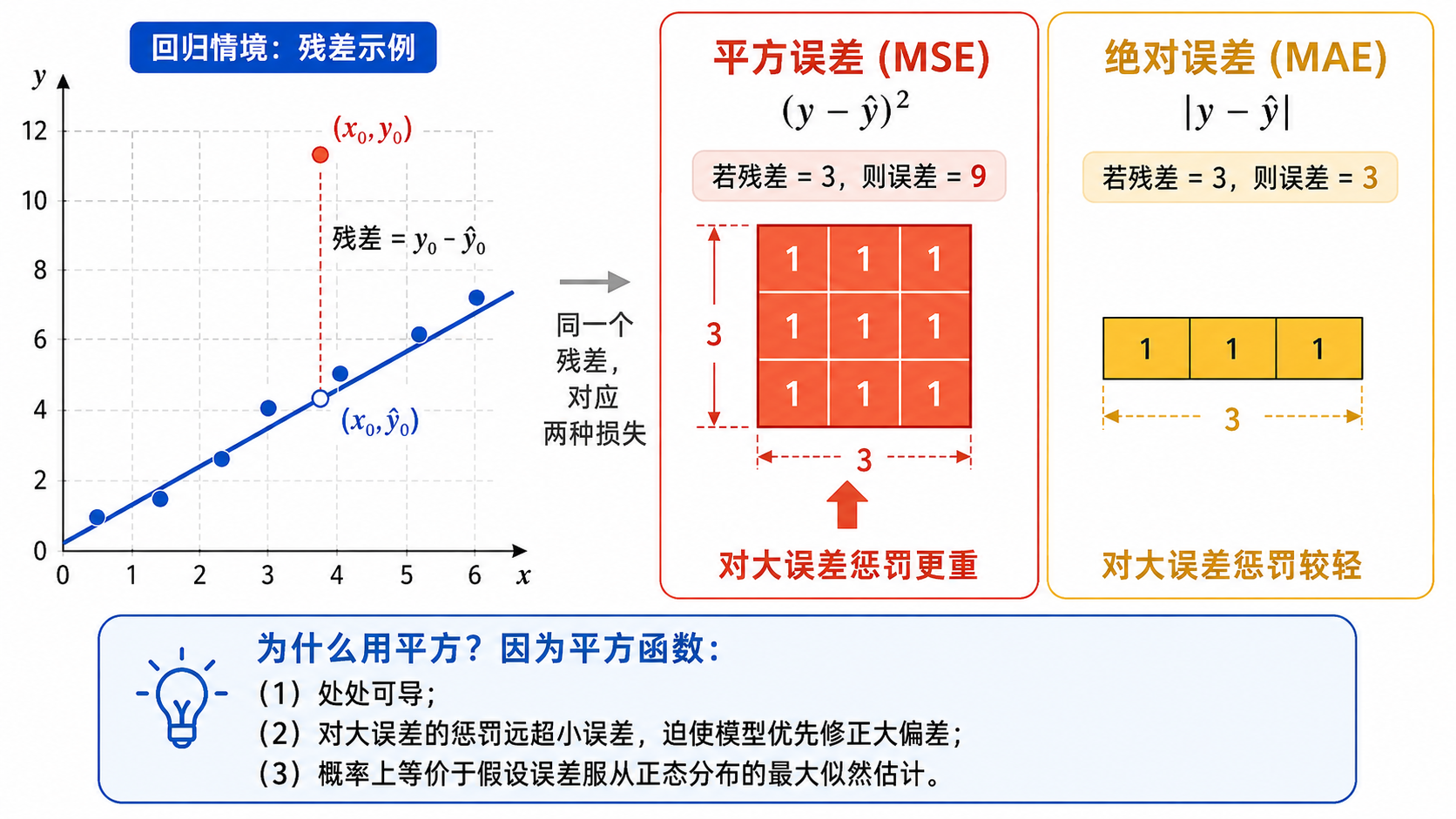
3.2 为什么用平方误差而不是绝对值?
这是一个值得深入思考的问题。让我们比较两种候选:
- 绝对值误差(MAE):
—— 对所有误差一视同仁 - 平方误差(MSE):
—— 对大误差给予更大的惩罚
选择平方误差的关键原因:
可微性:绝对值函数在
处不可导,而平方函数处处光滑可导。这使得我们可以使用梯度下降法来优化。 对大误差更敏感:平方函数放大了大误差的惩罚。一个误差为 10 的样本,在 MSE 中的惩罚是 100,在 MAE 中仅为 10。对于回归任务,大偏差通常意味着模型质量明显下降,应受到更强的纠正。
概率解释:如果假设误差服从正态分布
,那么最小化 MSE 等价于最大似然估计(MLE)。 凸性:MSE 是关于参数
的凸函数,意味着只有一个全局最小值,不会被卡在局部最小值中。
3.3 MSE 的几何意义
在几何上,线性回归是在寻找一个超平面,使得所有数据点到该超平面的竖直距离(残差)的平方和最小。这被称为最小二乘法(Ordinary Least Squares, OLS)。
对于二维情况(
4. 梯度下降:「走下坡路」的智慧
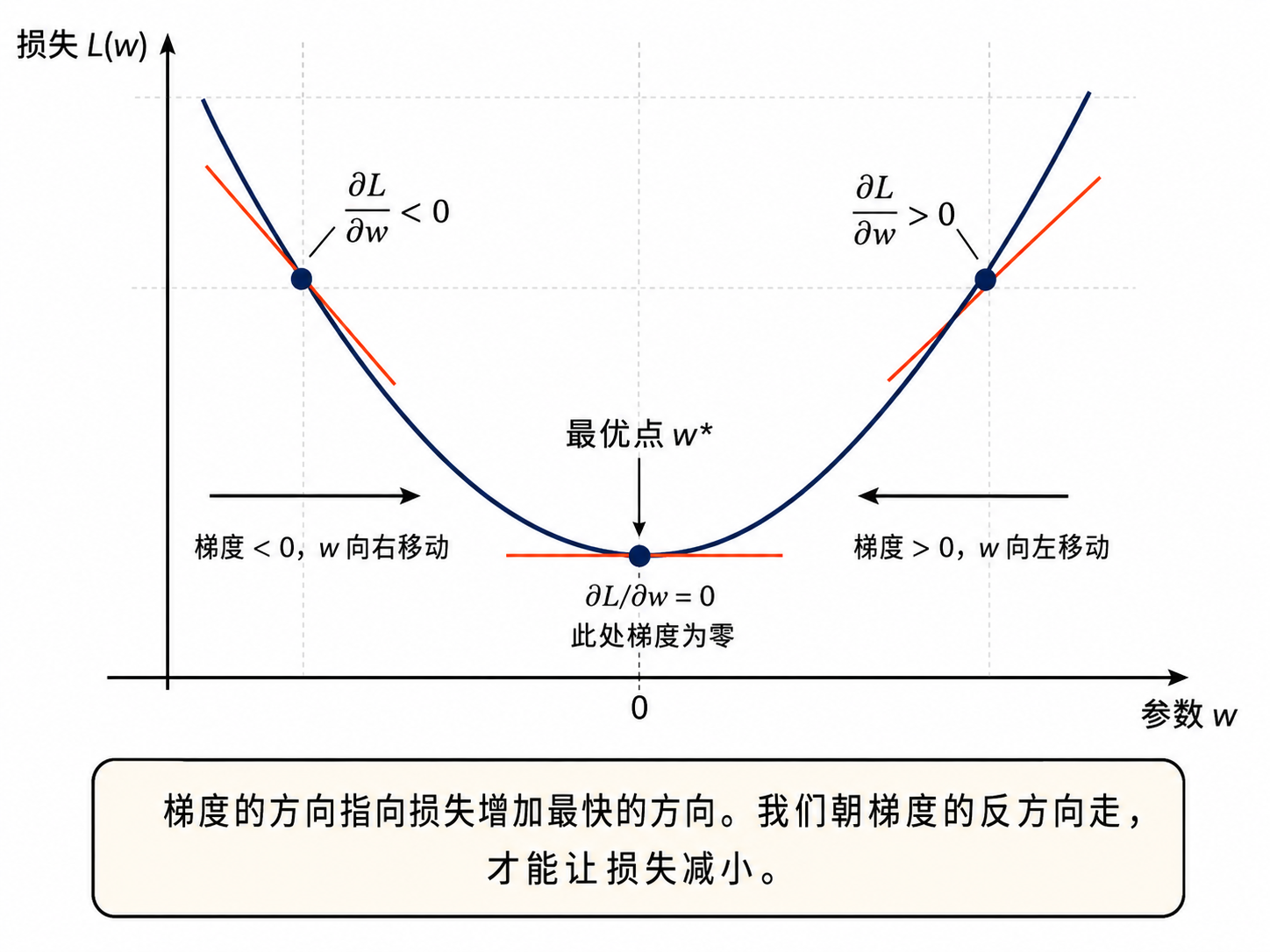
4.1 直觉
想象你蒙着眼睛站在一座山上,目标是走到山谷的最低点。你唯一的信息是脚下的坡度(斜率)。一个自然的策略是:每次都朝最陡的下坡方向走一小步,重复直到你感觉地面变平了。这就是梯度下降的核心思想。
4.2 数学表述
梯度下降的更新规则:
其中
4.3 推导 MSE 的梯度
对于简单的一元线性模型
对
对
梯度下降更新:
5. 正规方程:封闭解
对于线性回归,我们不仅可以梯度下降,还可以直接求出解析解。
5.1 推导
将损失函数写成矩阵形式:
对
解得:
这就是著名的正规方程(Normal Equation)。
5.2 梯度下降 vs. 正规方程
| 方法 | 优点 | 缺点 |
|---|---|---|
| 梯度下降 | 适用于大规模数据( | 需要选择学习率;需要多次迭代;可能收敛到局部最优点(对非凸函数) |
| 正规方程 | 不需要选择学习率;不需要迭代;一次性得到精确解 | 计算 |
在实际工程中,当
6. 从梯度下降到随机梯度下降
6.1 批量梯度下降(Batch GD)
每次更新使用全部
优点:梯度计算精确,收敛稳定。 缺点:每步都要处理全部数据,当
6.2 随机梯度下降(Stochastic GD, SGD)
每次更新使用1 个随机样本的梯度:
优点:每次更新极快,可以跳出局部最优点(噪声有正则化作用)。 缺点:梯度估计有噪声,收敛路径不稳定。
6.3 小批量梯度下降(Mini-batch GD)
每次更新使用**一小批(batch)**样本(如 32、64、128 个):
取两者之长:比 SGD 稳定,比 Batch GD 快。这是深度学习中最常用的形式。
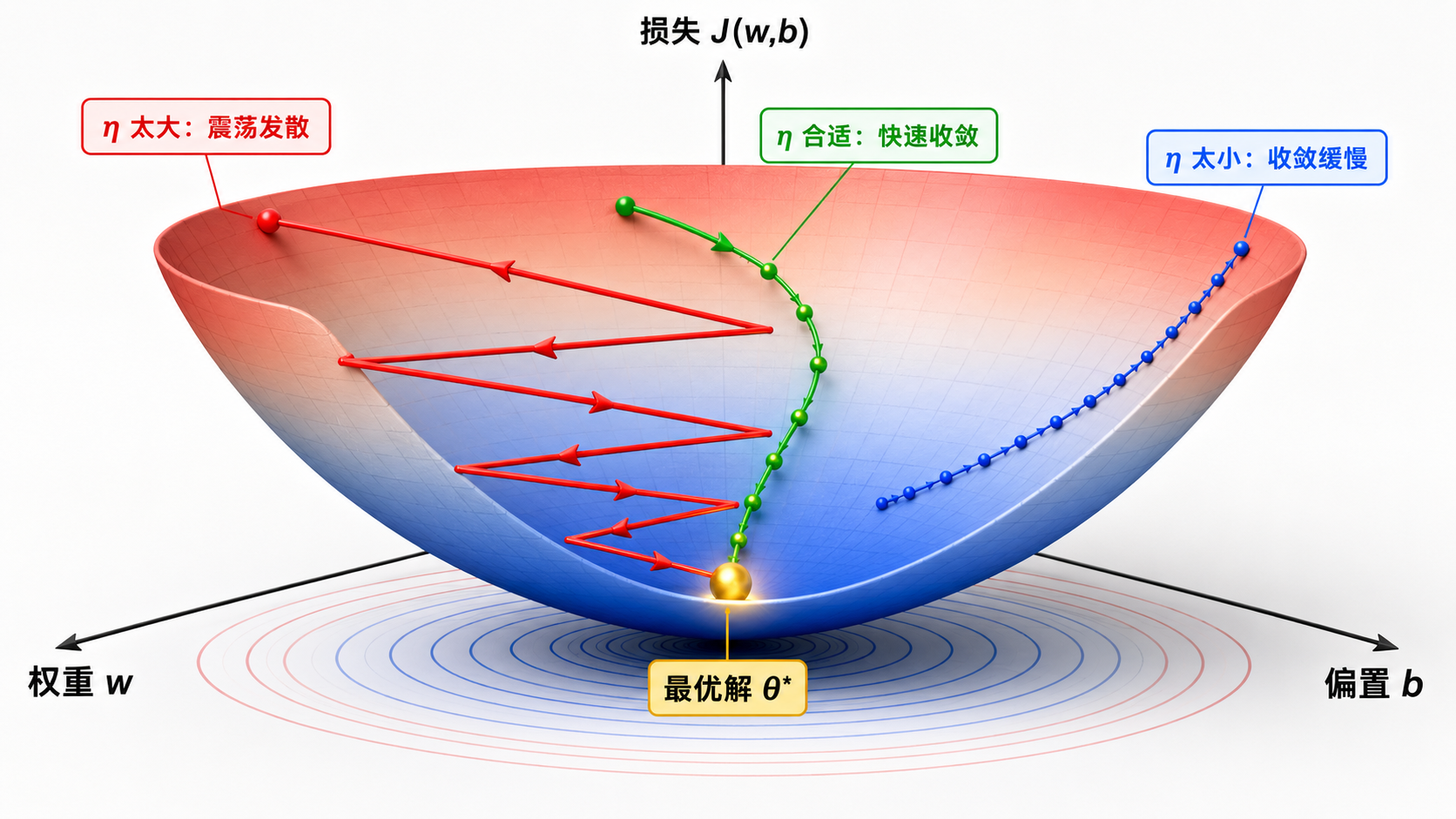
7. 学习率的选择
学习率
太大:参数更新幅度过大,可能在损失函数曲面上来回震荡,甚至发散(损失越来越大)。 太小:收敛速度极慢,可能需要数万个 epoch 才能到达最优解附近。 适中:在合理的时间内收敛到最小值。
实际中的学习率选择策略:
- 学习率衰减:随着训练进行逐步减小学习率
- 学习率预热:开始用很小学习率,逐步增大到目标值
- 自适应学习率:每个参数有不同的学习率(Adam、RMSprop 等)
本章总结
线性回归是机器学习中最简单但最重要的模型。它教会我们:
- 模型 = 假设空间:线性模型假设输出是输入的线性组合
- 损失 = 优化目标:MSE 衡量预测与真实的差距,且具有优美的数学性质
- 梯度下降 = 优化方法:沿着损失函数的梯度方向,一步步走向最优解
- 正规方程 = 解析解:对于线性模型,我们甚至可以直接写出最优参数的公式
这些概念构成了所有机器学习模型(包括最深的神经网络)的基础框架。第 3 章我们将看到,只需要在输出端加一个 sigmoid 函数,线性回归就能摇身一变成为分类利器——逻辑回归。
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.