ml11 隐马尔可夫模型 (HMM)
当观测背后隐藏着不可见的状态序列,如何从可见的"果"推断出隐藏的"因"?HMM 是时序概率建模的经典框架,三大问题贯穿始终:评估、解码、学习。
一、马尔可夫链基础
1.1 马尔可夫性质
一个随机过程
即:给定现在,未来与过去条件独立。当前状态
直觉:棋类游戏是马尔可夫性的完美体现——你只需要知道当前棋盘的状态,不需要记住之前 50 步的走法历史,就能决定下一步最优策略。
1.2 转移矩阵与平稳分布
马尔可夫链由状态空间
转移矩阵满足行和为 1(每一行是一个概率分布):
平稳分布(Stationary Distribution)
直观理解:如果当前状态服从
1.3 细致平衡(Detailed Balance)
一个更强的条件是细致平衡:
细致平衡意味着:从状态
二、隐马尔可夫模型结构
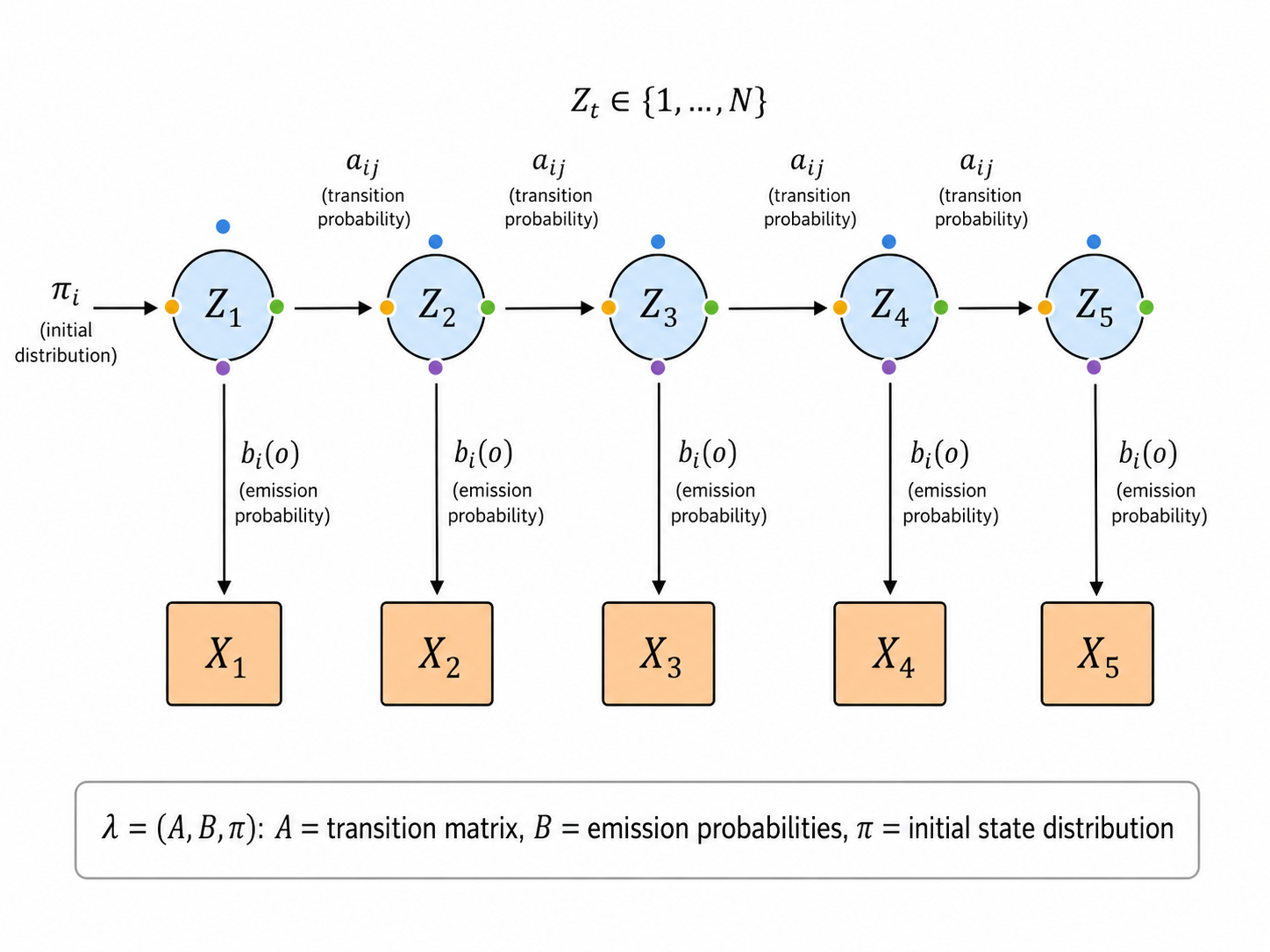
2.1 模型定义
HMM 是一个双重随机过程:
- 隐藏层:一个不可观测的一阶马尔可夫链
(状态序列), - 观测层:在每个时刻
,隐藏状态 生成一个观测
HMM 由三个参数完全确定:
| 参数 | 符号 | 含义 |
|---|---|---|
| 初始状态分布 | ||
| 状态转移矩阵 | ||
| 发射概率 |
记完整的 HMM 为
2.2 HMM 的三个基本问题
HMM 理论框架的三个核心问题(Rabiner, 1989):
| 问题 | 输入 | 输出 | 算法 |
|---|---|---|---|
| 评估(Evaluation) | 观测序列 | 前向算法(Forward Algorithm) | |
| 解码(Decoding) | 观测序列 | 最可能的状态序列 | 维特比算法(Viterbi Algorithm) |
| 学习(Learning) | 观测序列 | 最优参数 | Baum-Welch 算法(EM for HMM) |
三、前向算法(Forward Algorithm)——评估问题
3.1 问题
给定观测序列
3.2 朴素方法的指数爆炸
朴素计算需要枚举所有可能的状态序列:
状态序列有
3.3 前向算法的动态规划
前向算法利用 HMM 的马尔可夫结构,通过动态规划将复杂度降为
定义前向概率
即在时刻
递推公式:
初始化(
递推(
终止:
![前向算法递推图示:格子图(trellis)显示 t-1 时刻所有状态 i 以权重 α_{t-1}(i) 指向 t 时刻状态 j,每条边标注转移概率 a_{ij},t 时刻节点 j 标注 α_t(j) = [Σ_i α_{t-1}(i)·a_{ij}] · b_j(x_t)](/learn-ai/assets/ml11-02-forward-algorithm.Cuxer0xp.png)
3.4 前向-后向算法
后向概率
即在时刻
递推(从后往前,
初始:
前向-后向算法联合使用时可以计算"在时刻
四、维特比算法(Viterbi Algorithm)——解码问题
4.1 问题
找到最有可能生成观测序列
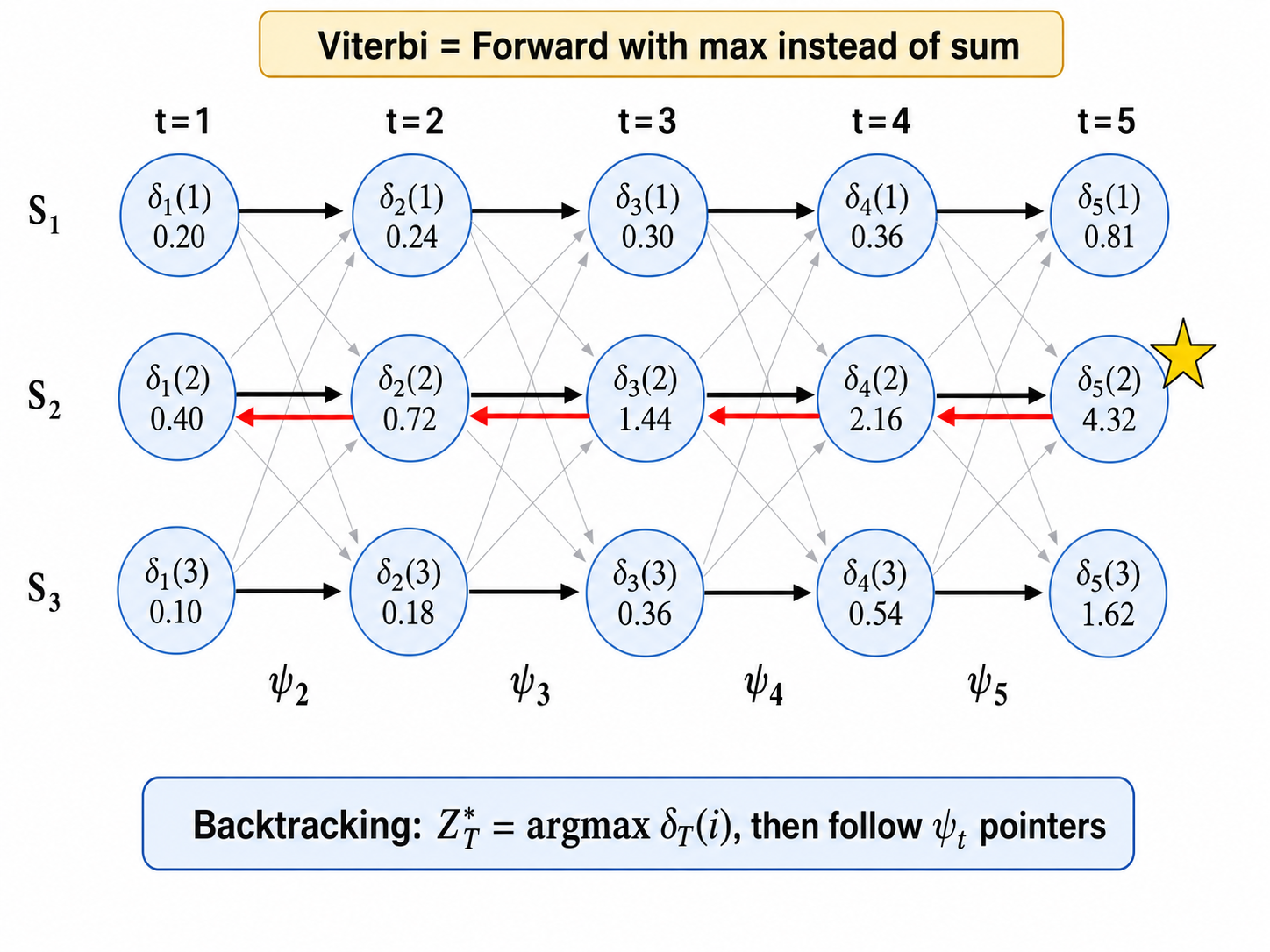
4.2 Viterbi 算法
与前向算法结构相似,但用最大化替换了求和。
定义
递推:
初始化:
递推(
同时记录"回溯指针"(backpointer):
终止:最优路径概率为
前向 vs Viterbi 对比:前向算法用 sum(
,边际化所有可能的过去路径),Viterbi 用 max( ,只保留一条最优路径)。两者的递推结构完全相同,只是操作符从 sum 变为 max。
五、Baum-Welch 算法——学习问题
5.1 EM 框架
Baum-Welch 算法是 EM 算法在 HMM 中的特例。隐变量是状态序列
5.2 E 步:计算期望充分统计量
用当前参数
状态占用概率
状态转移概率
5.3 M 步:更新参数
对于离散观测:
直觉:
六、HMM 在词性标注(POS Tagging)中的应用
6.1 POS Tagging 作为 HMM
词性标注(Part-of-Speech Tagging)是 HMM 的经典应用:
- 隐藏状态:词性标签(名词、动词、形容词...)
- 观测:具体的词汇
- 转移概率
:一个词性后面跟另一个词性的概率(如 "形容词 → 名词" 比 "形容词 → 形容词" 更常见) - 发射概率
:给定词性 ,产生词 的概率(如 "run" 作为动词比作为名词更常见)
6.2 Viterbi 解码 POS
给定一个句子(观测序列),Viterbi 算法可以找到最可能的词性标注:
Obs: The cat sat on the mat
↓ ↓ ↓ ↓ ↓ ↓
State: DET NOUN VERB PREP DET NOUN模型参数
七、HMM 的实用考量
7.1 数值下溢
前向/后向算法中涉及大量概率连乘(每个
缩放版本的前向算法:
其中
7.2 状态数量选择
HMM 的状态数
- 领域知识:如 POS tagging 中词性标签的数量是已知的
- 交叉验证:在留出集上评估困惑度(perplexity)
- 信息准则:如 BIC(贝叶斯信息准则)
7.3 HMM 的局限性
| 局限 | 说明 |
|---|---|
| 一阶马尔可夫假设 | 当前状态只依赖前一个状态,可能不足以捕捉长期依赖 |
| 观测条件独立 | |
| 离散状态 | 标准 HMM 的状态是离散的,连续状态需用卡尔曼滤波 |
| 指数长度分布 | HMM 隐含的状态持续时间的分布是几何分布,可能不符合实际 |
本章总结
| 概念 | 一句话 |
|---|---|
| 马尔可夫性质 | |
| HMM 三元组 | |
| 前向算法 | |
| 后向算法 | |
| Viterbi 算法 | 用 max 替换 sum 的前向算法 + 回溯指针 |
| Baum-Welch | EM for HMM:E 步计算 |
| 数值下溢 | 用缩放或 log 空间防止概率连乘的下溢 |
| POS Tagging | HMM 经典应用:隐藏状态 = 词性,观测 = 词汇 |
| 格子图(Trellis) | HMM 的"展开图",展示所有可能状态路径的时间网格 |
📥 Code
| File | View | Download |
|---|---|---|
| demo.py | Open | Download |
| exercise.py | Open | Download |
参考
- Rabiner, L. R. (1989). A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77(2), 257-286. [doi:10.1109/5.18626]
- Baum, L. E., Petrie, T., Soules, G., & Weiss, N. (1970). A Maximization Technique Occurring in the Statistical Analysis of Probabilistic Functions of Markov Chains. The Annals of Mathematical Statistics, 41(1), 164-171. [doi:10.1214/aoms/1177697196]
- Viterbi, A. J. (1967). Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm. IEEE Transactions on Information Theory, 13(2), 260-269. [doi:10.1109/TIT.1967.1054010]
- Jurafsky, D. & Martin, J. H. (2024). Speech and Language Processing (3rd ed.). Chapter 8: Sequence Labeling for Parts of Speech and Named Entities. [web]
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society: Series B, 39(1), 1-38. [doi:10.1111/j.2517-6161.1977.tb01600.x]